numpyの配列はndarrayという型で取り扱われます。
配列ndarrayを生成するための最も基本的な関数が、array関数です。
今回は、array関数の使用方法について整理しました。

array使用時の注意:型と要素数
array関数を用いてndarrayを生成する際の注意点を紹介します。
① 配列内の型は基本的に1種類
② 各次元の要素数は等しい
ndarrayをpythonのリストと比較しながら、これらの注意点について考えてみます。
ndarrayの構成
ndarrayの重要な属性を下図に整理しました。

ndarrayは、要素の型dtype、配列の形状shape、配列本体arrayから構成されます。
これをpythonのリストと比較しながら、注意点を確認してみましょう。
① 配列内の型は基本的に1種類
pythonのリストであれば、数字と文字列の混在が許されます。
my_list = [1, "A", 2, "B"] #問題ない
つまり、リスト内に2種類以上の型が混在しても問題ありません。
しかし、ndarrayでは、特殊な例外を除いて、数字の配列なら数字のみ、文字列の配列なら文字列のみで構成される必要があります。
x = np.array([1, "A", 2, "B"]) # エラーになる
pythonのリストとndarrayそれぞれの型の情報がどこに定義されているかを図解してみます。
pythonのリストの場合は、下図のように要素毎に型が定義されます。
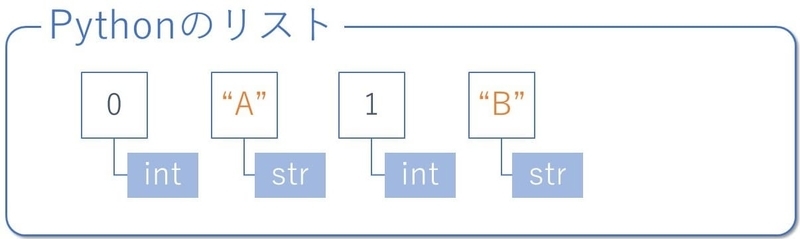
一方、ndarrayの場合は、ndarrayの属性dtypeとして定義され、各要素で共通です。

そのため、配列の型は基本的に1種類になります。
② 各次元の要素数は等しい
pythonのリストであれば、リスト内リストの要素数に関して制限はありません。
my_list = [[1], [2, 3], [4, 5, 6]] # 問題ない
ndarrayで数値の配列や文字列の配列を作成するためには、各次元の要素数は等しい必要があります。
x = np.array([[1], [2, 3], [4, 5, 6]]) # エラーは出ないが、期待する結果ではない。
この場合、要素の型はオブジェクト型という特殊な型になってしまいます。
配列計算では、主に要素の型をint型やfloat型にする必要があるため、これは望まない結果です。
float型の配列を用意するためには、次のように各次元の要素数を等しくします。
x = np.array([[1, 2, 3], [4, 5, 6]]) # 2×3の配列になる
以下の図は、pythonのリストとndarrayそれぞれの要素数の情報がどこに定義されているかを図解してみます。
pythonのリストの場合は、下図のように要素数がリスト毎に定義されます。

一方、ndarrayの場合は、下図のようにndarrayの属性shapeとして定義されます。

そのため、各次元の要素数は等しい必要があります。
一次元配列(ベクトル)の生成
array関数を利用して一次元の配列を生成します。
一次元配列はベクトルを表現する際に使用します。
【基本】リストから生成
arrayにPythonのリストを与えて、ndarrayを生成します。
# 引数に直接リストを記述
v = np.array([1, 2, 3])
# v → array([1, 2, 3])
# 引数にリストの変数を与える
a = [-1, 2, -3]
u = np.array(a)
# u → array([-1, 2, -3])
明示的に指定しない限り、ndarrayの要素の型dtypeは、リストの要素から自動で推定されます。
概ね次のルールを覚えておくと良いです。
・数値のリストの場合:浮動小数点float
・複素数を含む場合:複素数cfloat
・文字列を1つでも含む場合:文字列
numpyは数値計算用のライブラリなので、数値のリストを与えることが多いです。
そのため結果としてdtypeは浮動小数点になることが多いと思います。
リストの結合を利用|複数の数字の繰り返し時
次のように複数の数字を繰り返すリストを作成することを考えます。
weight = [0, 1/4, 1/4, 1/8, 1/8, 1/8, 1/8]
x = np.array(weight)
# x → array([0. , 0.25 , 0.25 , 0.125, 0.125, 0.125, 0.125])
数回程度の繰り返しであれば、手打ちでも対応できます。
しかし、繰り返し回数が増えれば手打ちでの対応は困難です。
数字の繰り返しは、pythonのリストの特性を利用します。
・リストは+で結合できる。[0] + [1/4, 1/4] → [0, 1/4, 1/4]
・要素は*で繰り返せる。[1/8]*4 → [1/8, 1/8, 1/8, 1/8]
先ほどの例は、次のように書き直すことができます。
x = np.array([0] + [1/4]*2 + [1/8]*4)
# x → array([0. , 0.25 , 0.25 , 0.125, 0.125, 0.125, 0.125])
リストの結合+、繰り返し*を利用すると、記述が容易になって可読性もあがります。
リスト内包表記を利用|規則的な数列を作成
数列を扱う場合には、リスト内包表記を利用すると便利な場合があります。
例として、平方数のarrayを作成します。
# 平方数のarray
x = np.array([i**2 for i in range(10)])
# x → array([ 0, 1, 4, 9, 16, 25, 36, 49, 64, 81])
リスト内包表記には、条件を追加することもできます。
# 平方数のうち3の倍数でarrayを作成
x = np.array([i**2 for i in range(25) if i**2 % 3 == 0])
# x → array([ 0, 9, 36, 81, 144, 225, 324, 441, 576])
多次元配列の生成
ネストしたリストをarray関数に与える方法と、一次元配列をreshapeする方法を紹介します。
【基本】ネストしたリストから生成
np.arrayにPythonのネストしたリストを与えて、ndarrayを生成します。
# 引数に直接リストを記述
A = np.array([[1, 2, 3], [4, 5, 6]])
# A → array([[1, 2, 3],
# [4, 5, 6]])
# 引数にリストの変数を与える
b = [[-1, -2, -3], [-4, -5, -6]]
B = np.array(b)
# B → array([[-1, -2, -3],
# [-4, -5, -6]])
次のように改行を入れると、次元毎の要素数が等しいか確認するのに便利です。
# 引数にリストの変数を与える
# 引数にリストの変数を与える
c = [[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]
C = np.array(c)
# C → array([[1, 2, 3],
# [4, 5, 6],
# [7, 8, 9]])
繰り返しですが、引数はネストしたリストです。
ネストしていない複数のリスト与えると、エラーになります。
A = np.array([1, 2, 3], [4, 5, 6]) # エラーになります
一次元配列をリシェイプ
各種チュートリアルや教本などでよく見るテクニックです。
①リストから一次元配列を作成
②reshapeメソッドで配列の形状を多次元配列化
A = np.array([1, 2, 3, 4, 5, 6])
B = A.reshape((2, 3))
# A → array([1, 2, 3, 4, 5, 6])
# B → array([[1, 2, 3],
# [4, 5, 6]])
reshapeを使用するときは、次のことに注意しましょう。
・引数はタプル( )で与える。
・reshapeメソッドは、形状を変化した配列を新たに生成する。
2つ目は特に注意が必要で、上の例ではA自体の形状は変化しません。
そのため、Aを変形して、Bに代入する必要があります。
一次元配列を生成したくない場合は、次のように一行で記述することもできます。
A = np.array([1, 2, 3, 4, 5, 6]).reshape((2, 3))
# A → array([[1, 2, 3],
# [4, 5, 6]])
連続する数字の配列を生成するarrange関数との組み合わせもよく見る手法です。
arrange関数は、pythonのrange関数のnumpy版です。
A = np.arange(9).reshape((3, 3))
# A → array([[0, 1, 2],
# [3, 4, 5],
# [6, 7, 8]])