pandasの.plot()メソッドを使用すると、簡単にDataFrameをグラフ化することができます。
しかし、いざ.plot()でグラフを描こうとすると次のような疑問に直面することも…
- プロットするデータの指定方法は?
- グラフの種類変更や軸の設定はどうするの?
Matplotlibとの連携はどうすればいいの?
そこで、今回は.plot()でグラフを描画する方法、Matplotlibとの連携方法を実例付きでわかりやすく解説していきます。
実例で見る!plot()メソッドによるグラフ化
最も簡単な.plot()の使い方は次のようにメソッドを実行する方法です。
DataFrameのグラフ化|df.plot()- デフォルト:インデックス列をx、各データ列をyとする折れ線グラフ出力
次のようなsinとcosのサンプルデータ使って、.plot()の実行例を確認してみましょう。
theta = np.linspace(0,2*np.pi) # 0~2πのndarrayを生成
df = pd.DataFrame({"Sine":np.sin(theta), "Cosine":np.cos(theta),
"-Sine":-np.sin(theta),},index=pd.Index(theta, name="Theta"))
print(df)
# Sine Cosine -Sine
# Theta
# 0.000000 0.000000e+00 1.000000 -0.000000e+00
# 0.128228 1.278772e-01 0.991790 -1.278772e-01
# 0.256457 2.536546e-01 0.967295 -2.536546e-01
# ~省略~
# 6.154957 -1.278772e-01 0.991790 1.278772e-01
# 6.283185 -2.449294e-16 1.000000 2.449294e-16
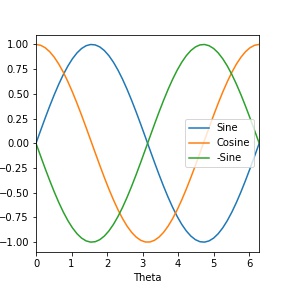
デフォルト設定では、インデックス列をx、各データ列をyとしたグラフができます。
df.plot()
たった一行ですが、次のようなグラフが出力されます。

DataFrameを簡単にグラフ化することができましたね。
実際には、プロットするデータ列の選択やグラフの見栄え変更など様々な設定をしたいものだと思います。
以下では、.plot()メソッドの様々な設定方法について紹介していきます。
プロットデータの選択|x, y
.plot()のデフォルト設定では、インデックス列をx、各データ列をyとする折れ線グラフを出力します。
特定の列をxの値と指定したり、プロットするデータ列を指定したりする際には、それぞれ引数x, yを指定します。
| 設定内容 | 引数名 | 設定方法、設定例 |
|---|---|---|
| xの値にするデータ列の指定 | x |
x="横軸にしたい列名" |
| プロットするデータ列の指定 | y |
y="プロットする列名" またはy=["列名1", "列名2"…] |
次のように、θ, sin, cos, -sinをデータに持つDataFrameを例に、x, yの指定例を見てみましょう。
theta = np.linspace(0,2*np.pi) # 0~2πのndarrayを生成
df = pd.DataFrame({"Theta": theta, "Sine":np.sin(theta), "Cosine":np.cos(theta)})
print(df)
# Theta Sine Cosine
# 0 0.000000 0.000000e+00 1.000000
# 1 0.128228 1.278772e-01 0.991790
# 2 0.256457 2.536546e-01 0.967295
# ~省略~
# 49 6.283185 -2.449294e-16 1.000000
デフォルト設定では、横軸がインデックス列(0, 1, 2, …)になってしまいます。
# デフォルト設定で実行
df.plot()
本来x軸にしたい"θ列"までプロットされてしまいますね。

次にx="Theta"によって、"θ列"をx軸に設定してみます。
# Theta列をxの値に指定
df.plot(x="Theta")
次のように横軸が"θ列"になりました。
続いて、y=["Sine", "Cosine"]を指定して、プロットする列を指定してみます。
# Theta列をxの値に指定
df.plot(x="Theta", y=["Sine", "Cosine"])
"Sine列"と"Cosine列"のみがプロットされて、"-Sine列"はプロットされないようになりました。

x, yでプロットするデータ列を指定できるので、簡単なデータ確認用のグラフはすぐに作れますね。
グラフ全般の表示設定
次にグラフの全般設定に関して、整理していきましょう。
グラフ全般の表示設定に関連する引数は次の通りです。
| 設定内容 | 引数名 | 設定方法、設定例 |
|---|---|---|
| 描画領域のサイズ | figsize |
グラフサイズ(インチ):(width, height) |
| グラフのタイトル | title |
タイトル設定:
|
| グラフ下部にData表を表示 | table |
False(デフォルト):表の非表示True:表の表示 |
グラフ領域のサイズ|figsize
グラフ領域のサイズを指定する場合は、次のようにfigureを指定します。
figsize=(width, height)
例えば、widthとheightに同じ値を設定すると、描画領域が正方形になります。
df.plot(figsize=(4,4))
次のように描画領域が正方形になったグラフが生成されます。
グラフタイトル|title
グラフにタイトルを設定には、次のようにtitleを指定します。
- グラフ全体のタイトル:
title="タイトル名" - サブプロット毎のタイトル:
title=["タイトル1", "タイトル2",…]
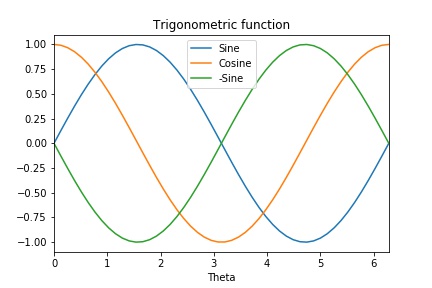
まずは、グラフ全体にタイトルを設定してみます。
df.plot(title="Trigonometric function")
次のようにグラフ上部にタイトルが表示されます。
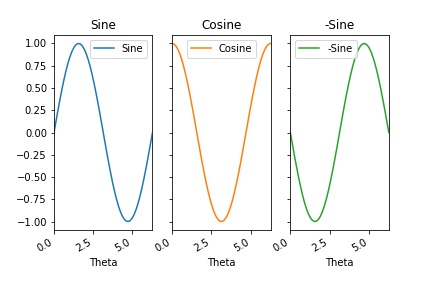
次にサブプロット毎にタイトルを設定してみます。
df.plot(title=["Sine", "Cosine", "-Sine"], subplots=True, layout=(1,3), sharey=True)
ここでは、タイトルや軸目盛がお互いに被らないようにレイアウトも調整しています。
サブプロットの設定|subplot
詳細なサブプロット設定をする場合は、Axes経由でMatplotlibと連携したほうが便利ですが(後述)、引数で簡単なサブプロット化も可能です。
| 設定内容 | 引数名 | 設定方法、設定例 |
|---|---|---|
| 各グラフをサブプロット化するか指定 | subplot |
False(デフォルト):サブプロット化しないTrue:サブプロット化する |
| サブプロットのレイアウト | layout |
[リスト]等で縦横サブプロット数指定:layout=(縦方向個数, 横方向個数) |
| サブプロット間での軸目盛共有 | sharexsharey |
False(デフォルト):軸を共有しないTrue:軸を共有 |
各データを個別のサブプロットにプロットする場合には、subplot=Trueを指定します。
df.plot(subplots=True)
次にように縦方向に3つのサブプロットが並んだグラフが作成されます。

サブプロットのレイアウトを変更する場合には、layoutで指定します。
layout=(縦方向サブプロット個数, 横方向のサブプロット個数)
横方向に3つのサブプロットを並べてみましょう。
df.plot(subplots=True, layout=(1,3))
次のように、横方向に3つのサブプロットが並びます。

sharex, shareyを使用すると、それぞれ横軸、縦軸をサブプロット間で共有することができます。
今回の場合は、縦軸がサブプロットで重なり合っているので共有してみましょう。
df.plot(subplots=True, layout=(1,3), sharey=True)
次にように縦軸が共有されます。

各サブプロットにタイトルを設定する場合は、title=["タイトル1", "タイトル2",…]のように指定します。
df.plot(title=["Sine", "Cosine", "-Sine"], subplots=True, layout=(1,3), sharey=True)
次のように各サブプロットにタイトルが設定されました。
軸周りの設定まとめ
軸周りの設定に関する引数は、散漫としていて若干わかりにくい部分があります。
そこで、次の3つの項目にわけて解説していきたいと思います。
- 軸目盛の設定
- 2軸グラフ化
Matplotlibと連携した軸の詳細設定
次の常用対数のデータを使用して、各種挙動を確認していきましょう。
x = np.linspace(1, 1000)
y = np.log10(x)
z = np.log10(10*x)
df = pd.DataFrame({"x":x, "y":y, "z":z}).set_index("x")
print(df)
# y z
# x
# 1.000000 0.000000 1.000000
# 21.387755 1.330165 2.330165
# ~省略~
# 1000.000000 3.000000 4.000000
デフォルト設定だと次のようなグラフになります。

目盛りを設定を変更していきましょう。
軸目盛の設定
| 設定内容 | 引数名 | 設定方法、設定例 |
|---|---|---|
| 軸目盛 | xticksyticks |
表示するメモリの[リスト]等:[0, 1, 2, 3, …] |
| 軸の最大値・最小値 | xlimylim |
(最小値, 最大値)で指定 |
| 対数表示 | logxlogwloglog |
False(デフォルト):対数目盛にしないTrue:対数目盛化 |
| 目盛り線の表示 | grid |
False(デフォルト):目盛線非表示True:目盛線表示 |
| 軸目盛のフォントサイズ | fontsize |
フォントサイズを数値で指定 |
目盛りを個別に設定する場合には、xticks, yticksに表示する目盛りの[リスト]等を与えます。
df.plot(xticks=[0, 500, 1000], yticks=[0, 2, 4])
次のように指定した値のみ表示されます。

最大値と最小値だけを指定する場合は、xlim, ylimにそれぞれ(最小値, 最大値)を渡します。
df.plot(xlim=(0,200), ylim=(0,5))
次のように最大・最小値が設定されます。

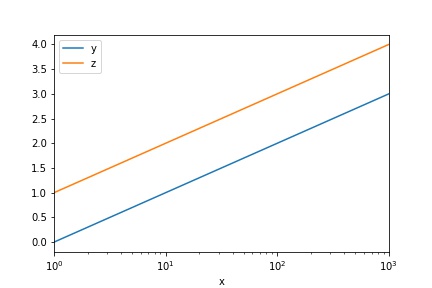
対数軸に設定する場合は、対数に設定する軸に応じてlogx, logy, loglog =Trueを指定します。
df.plot(grid=True)
次のように横軸が対数になります。
目盛り線を設定する場合は、grid=Trueを指定します。
df.plot(grid=True)
次のように目盛り線が表示されます。

2軸グラフ化
グラフを2軸化する場合には、secondary_yに列名を指定します。
secondary_y=["二軸でプロットする列名",…]
z列を2軸にしてグラフを作成してみましょう。
df.plot(secondary_y=["z"], ylim=(0,4))
次のように右側に2軸が表示されます。

Matplotlibでの詳細設定
Axesオブジェクト経由でMatplotlibと連携すれば、細かい軸設定も可能です。
ラベル名設定や目盛り線の設定例を見てみましょう。
fig, ax = plt.subplots()
df.plot(ax=ax)
ax.set_xlabel("x-label")
ax.set_ylabel("y-label")
ax.minorticks_on()
ax.grid(which = "major", color="gray", linewidth=0.5)
ax.grid(which = "minor",color = "gray", linestyle="--", linewidth=0.5)
次のような軸ラベルや目盛り線が設定されたグラフが出力されます。

Axesオブジェクトを使用したMatplotlibの軸周りの設定については、次の記事で詳しく解説しています。

Axes経由でMatplotlibと連携
次のようにAxesオブジェクトを経由して、pandasの.plot()メソッドとMatplotlibを連携することができます。
- 既存
Axesにグラフ作成する場合:.plot(ax=既存Axes) .plot()で生成したAxes利用:ax=df.plot()でaxを受け取る
以下で、具体的な使い方を見ていきましょう。
MatplotlibのAxes作成方法については、次の記事も参考にしてみてください。

既存Axesを指定|ax=…
.plot()メソッドの引数axで、グラフを描画するAxesオブジェクトを指定することも可能です。
例として、plt.subplots()でAxes(サブプロット)を生成して、df.plot(ax=…)に渡してみます。
fig, axes = plt.subplots(2,2,tight_layout=True)
df.plot(ax=axes[0,0],y=["Sine"])
df.plot(ax=axes[1,1],y=["Cosine"])
次のように指定した位置だけにグラフが描かれます。

MatplotlibのFigure, Axesオブジェクトの機能を利用したいときに便利ですね。
例えば、グラフの見栄えをよくするためにtight_layoutを利用することも多いかと思います。

.plot()で生成したのAxes利用
既存のAxesにプロットを作成するのとは、逆に.plot()で作成したAxesオブジェクトを後から利用することも可能です。
.plot()メソッドはAxesオブジェクトまたはそのリストを返します。
- サブプロット無しパターン:
df.plot()→Axesオブジェクト単体 - サブプロット有りパターン:
df.plot(subplot=True)→[Axesオブジェクトのndarray]
Axesオブジェクトを受け取れば、そこに追加でグラフを描いたり、グラフを保存したりすることもできます。
ax = df.plot()
# 受け取ったaxにプロットや水平線を追加
ax.plot([0,2*np.pi], [0,0], linestyle="--", linewidth=1, color="black")
ax.hlines(0.5, 0, 2*np.pi, linestyle="--", linewidth=1, color="gray")
ax.hlines(-0.5, 0, 2*np.pi, linestyle="--", linewidth=1, color="gray")
df.plot()メソッドでは指定できなかった水平線なども追加出来て便利ですね。

作成したグラフの保存
.plot()で作成したAxesオブジェクトを利用すると、グラフを画像として保存することが可能です。
AxesオブジェクトからFgireオブジェクトに戻って、Figure.savefig()メソッドを利用します。
ax = df.plot()
ax.figure.savefig("保存名")
MatplotlibのFigureについては、次の記事で詳しく解説しています。
Matplotlibの全体的な使い方については、次の記事にまとめています。

グラフ種類変更
デフォルトでは折れ線グラフが作成されますが、引数kindでグラフの種類を変更することができます。
kind="グラフの種類"
主な選択できるグラフの種類は以下の通りです。
| グラフの種類 | 指定名 |
|---|---|
| 折れ線グラフ(デフォルト) | "line"(またはkindの指定を省略) |
| 棒グラフ | 縦棒グラフ:"bar"横棒グラフ: "barh" |
| ヒストグラム | "hist" |
| 面グラフ | "area" |
| 円グラフ | "pie" |
| 散布図 | "scatter" |
| Hexbinマップ | "hexbin" |
さらに、追加でMatplotのキーワード引数を指定して、グラフの見た目などを変更することができます。
例えば、折れ線グラフの場合は、次のような設定が可能です。
color:各折れ線の色marker:マーカー(プロット)の形状linestyle:線のスタイル
各グラフの描き方について、キーワード引数の指定も含めて個別に確認していきましょう。
折れ線グラフ|kind="line"
.plot()のデフォルト設定では、折れ線グラフが描画されます。
df.plot() or df.plot(kind="line")
折れ線グラフの見た目設定用の主なキーワード引数としては、次のものがあります。
| 設定内容 | キーワード引数名 | 設定例 |
|---|---|---|
| 各折れ線の色 | color |
色の名前やそのリストなど:
|
| マーカー(プロット)の形状 | marker |
プロットの種類を指定する文字列:
|
| マーカーの大きさ | markersize |
大きさを数値で指定:
|
| 線のスタイル | linestyle |
線の種類を指定する文字列:
|
| 線の太さ | linewidth |
線の太さを数値で指定:
|
| 折れ線の透明度 | alpha |
線の透明度:
|
例として、次のような簡単なデータのプロットを作成してみましょう。
x = np.arange(0,11)
df = pd.DataFrame({"X":x, "X**2":x**2, "10*X":10*x, "Zero": 0}).set_index("X")
# X**2 10*X Zero
# X
# 0 0 0 0
# 1 1 10 0
# 2 4 20 0
# 3 9 30 0
# 4 16 40 0
# 以下略
デフォルト設定では、次のようなグラフが描けます。
df.plot()

次にグラフの色、プロットの種類、線のスタイルを個別に設定してみます。
df.plot(color=["red", "blue", "green"], marker="o", markersize=6,
linestyle="--", linewidth=0.5, alpha=0.7)

グラフの見た目がだいぶ変わりましたね。
Matplotlibのpyplot()のキーワード引数については、次の記事で詳しく解説しています。

また、Matplotlibの色の指定方法については、次の記事で詳しく解説しています。

棒グラフ|kind="bar" or "barh"
棒グラフには、縦棒グラフと横棒グラフの2種類があります。
- 縦棒グラフ:
df.plot(kind="bar") - 横棒グラフ:
df.plot(kind="barh")- 積み上げ棒グラフにする場合は、
stack=Trueを追加指定
- 積み上げ棒グラフにする場合は、
棒グラフの主なキーワード引数としては、次のものがあります。
| 設定内容 | キーワード引数名 | 設定例 |
|---|---|---|
| 棒の太さ | width |
棒の太さを数値で指定:
|
| 棒の位置 | position |
|
| 棒の色 | color |
色の名前やそのリストなど:
|
| 棒の柄(テクスチャ) | hatch |
柄を指定する文字列:
|
| 枠線の色 | edgecolor |
色の名前やそのリストなど:
|
| 枠線の太さ | linewidth |
線の太さを数値で指定:デフォルト値=1.5 |
| 積み上げ棒グラフ変更 | stacked |
|
※正確にはpositionとstackedは.plot()メソッドの引数ですが、わかりやすさ優先でこちらに含めました。
例として、次のような簡単なデータで棒グラフを作成してみましょう。
area = ["A-city", "B-city", "C-city", "D-city"]
apple = [2, 3, 2, 3]
banana = [1, 2, 3, 4]
df = pd.DataFrame({"Apple":apple, "Banana":banana},
index=pd.Index(area, name="Area"))
print(df)
# Apple Banana
# Area
# A-city 2 1
# B-city 3 2
# C-city 2 3
# D-city 3 4
デフォルト設定では、次のようなグラフが描けます。
df.plot(kind="bar")
次のようなデフォルトの棒グラフが作成されます。

横棒グラフの場合には、kind="barh"を指定します。
df.plot(kind="barh")
次のように横棒グラフになります。

次にグラフの色、プロットの種類、線のスタイルを個別に設定してみます。
df.plot(kind="bar", color=["skyblue", "pink"],
edgecolor="gray", linewidth=0.5, hatch="x")
棒の色や太さなどグラフの見た目がだいぶ変わった棒グラフが出力されます。

最後にstacked=Trueを指定して、積み上げ棒グラフの作成例を確認しましょう。
df.plot(kind="bar", stacked=True, position=0,
color=["skyblue", "salmon"], edgecolor="black")
次のように積み上げ棒グラフになります。

Matplotlibの棒グラフのキーワード引数については、次の記事で詳しく解説しています。
また、Matplotlibの色の指定方法については、次の記事で詳しく解説しています。
ヒストグラム|kind=”hist"
棒グラフの主なキーワード引数としては、次のものがあります。
| 設定内容 | キーワード引数名 | 設定例 |
|---|---|---|
| ヒストグラムの各データ区間指定 | bins |
|
| ヒストグラムのスタイル | histtype |
|
| 棒の位置調整 | align |
棒の中心位置の調整:
|
| 相対度数で出力(確率密度関数など) | density |
|
| 累積値で出力(累積分布関数など) | cumulative |
|
| 複数データの積み上げ | stacked |
|
これらの他にもcolor, edgecolor, linewidth, linestyleなど、棒グラフと共通したキーワードがあります。
例として、次のような簡単なデータでヒストグラムを作成してみましょう。
x = np.random.randn(10000)
df = pd.DataFrame({"Random": x})
# Random
# 0 -1.645232
# 1 0.404695
# 2 -0.276144
# ... ...
# 9999 0.781517
デフォルト設定でヒストグラムを作成してみます。
df.plot(kind="hist")
自動で集計して、次のように正規分布のヒストグラムが作成できます。

次にヒストグラムの各データ区間指定してみます。
fig, axes = plt.subplots(1, 2,figsize=(9, 3), tight_layout=True)
# bins(データ区間)の個数を指定
df.plot(title="bins=100", ax=axes[0], kind="hist", bins=100, color="lightgreen")
# bins(データ区間)をユーザーで任意に定義
bins = [-4, -3.5, -3, -2.5, -2, -1.5, -1, -0.5, 0,
0.5, 1, 1.5, 2, 2.5, 3, 3.5, 4]
df.plot(title="bins=[User_List]", ax=axes[1], kind="hist", bins=bins, color="lightgreen")
見やすいように、2つのグラフをサブプロットで並べてみます(サブプロット作成方法については後述)。

binsを指定すれば、データ区間を細かくして集計したり、ユーザー側で定義したりすることも簡単ですね。
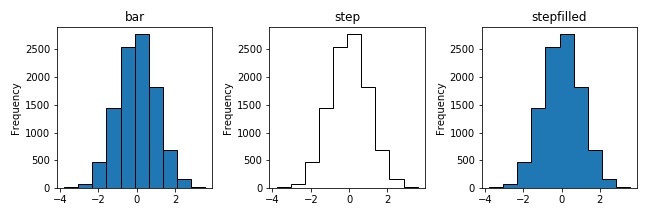
次にhisttypeを指定して、ヒストグラムのスタイルを変更する方法を確認しましょう。
fig, axes = plt.subplots(1, 3,figsize=(9, 3), tight_layout=True)
# bar: 棒グラフを並べたヒストグラム
df.plot(title="bar", ax=axes[0], kind="hist", histtype="bar", edgecolor="black", legend=False)
# step: 外枠だけのヒストグラム(塗りつぶし無し)
df.plot(title="step", ax=axes[1], kind="hist", histtype="step", edgecolor="black", legend=False)
# 外枠だけのヒストグラム(塗りつぶし有り)
df.plot(title="stepfilled", ax=axes[2], kind="hist", histtype="stepfilled", edgecolor="black", legend=False)
次のように見た目の異なるヒストグラムが作成されます。
最後に2つ以上のデータ列がある場合の挙動を確認してみましょう。
サンプルデータとして、正規乱数と正規乱数を+3だけシフトしたデータを用意します。
x = np.random.randn(10000)
x2 = x+3
df = pd.DataFrame({"Random": x, "Random2":x2})
# Random Random2
# 0 -1.308090 1.691910
# 1 0.450469 3.450469
# ... ... ...
# 9999 0.362715 3.362715
このDataFrameでヒストグラムを描くと、次のように個別で集計したヒストグラムが出力されます。
df.plot(kind="hist", bins=100, edgecolor="black",color=["blue","red"], alpha=0.5)
次のように一つのグラフ内に2つのヒストグラムが出力されます。

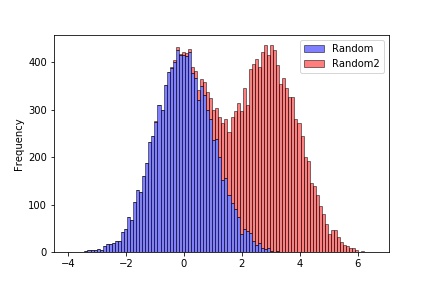
2つのデータを積み上げたい場合には、stacked=Trueを指定します。
ax = df.plot(kind="hist", bins=100, stacked=True, edgecolor="black",color=["blue","red"], alpha=0.5)
次のように2つのデータが積みあがったヒストグラムになります。
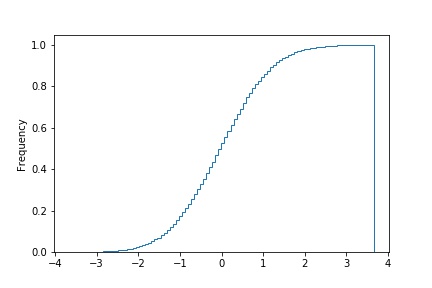
ヒストグラムの設定は他にもあり、densityやcumulativeを指定すると、累積分布関数として出力することもできます。
df.plot(kind="hist",cumulative=True, density=True, histtype="step", bins=100, legend=False)
次のような累積分布関数が出力されます。
ヒストグラムについての、より詳しい解説については次の記事を参考にしてみてください。
円グラフ|kind=”pie”
| 設定内容 | キーワード引数名 | 設定例 |
|---|---|---|
| 円グラフの開始角度 | startangle |
数値°で指定
|
| パイを反時計周りに並べる | counterclock |
|
| パイの色 | colors |
データ数と同じ要素数の[色のリスト]
|
| パイの強調 | explode |
データ数と同じ要素数の[リスト]
|
例として、次のような簡単なデータで円グラフを作成してみましょう。
x = np.random.randn(10000)
df = pd.DataFrame({"Random": x})
# Random
# 0 -1.645232
# 1 0.404695
# 2 -0.276144
# ... ...
# 9999 0.781517
デフォルト設定で円グラフを作成してみます。
df.plot(kind="pie",subplots=True)
円グラフの場合は、データ列の列数に関わらずsubplots=Trueを指定する必要があるようです。

デフォルト設定だと、円グラフの開始位置が3時の位置で、反時計回りにパイが並ぶため、若干違和感があります。
startangle=90, counterclock=Falseを指定して、Excel風の見た目にしてみましょう。
df.plot(kind="pie",subplots=True, startangle=90, counterclock=False)
次のようにExcel風の見慣れた円グラフになります。
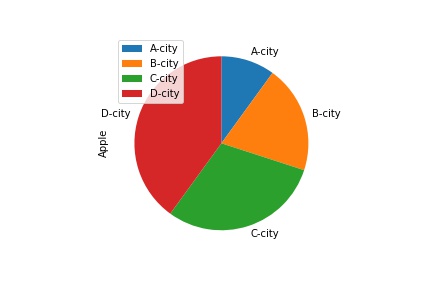
次にexplodeで、一部のパイを切り出して、強調表示してみます。
explode = [0,0,0.1,0]
df.plot(kind="pie",subplots=True, startangle=90, counterclock=False, explode=explode)
3つ目の要素(C-city)のパイが少し飛び出て強調表示されています

次にパイの色変更例を見てみましょう。
円グラフの場合は、colorではなく、colors引数で、各パイの色を指定します。
colors = ["red", "salmon", "magenta", "pink"]
df.plot(kind="pie",subplots=True, startangle=90, counterclock=False, colors=colors)
次のように各パイがユーザー指定の色になりました。

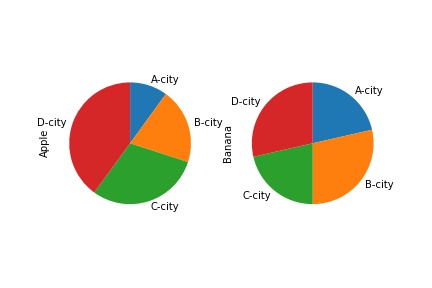
最後にDataFrameのデータ列が複数ある場合の挙動について確認しておきましょう。
area = ["A-city", "B-city", "C-city", "D-city"]
apple = [1, 2, 3, 4]
banana = [3, 4, 3, 4]
df = pd.DataFrame({"Apple":apple, "Banana":banana},index=pd.Index(area, name="Area"))
print(df)
# Apple Banana
# Area
# A-city 1 3
# B-city 2 4
# C-city 3 3
# D-city 4 4
df.plot(kind="pie",subplots=True, startangle=90, counterclock=False, legend=False)
次のようにそれぞれの列に対して円グラフが生成されます。
以下の記事では円グラフの詳細設定やドーナツグラフの作成方法について解説しています。

ぜひ参考にしてみてください!
散布図|kind=”scater”
散布図を作成する場合は、kind="scatter"を指定します。
x軸データとy軸データの組み合わせを、それぞれラベル名またはそのリスト等で次のように与えます。
- 1系列プロット:
df.plot(kind="scatter", x="x列ラベル名", y="y列ラベル名") - 多系列プロット:
df.plot(kind="scatter", x=["x1列ラベル名", "x2列ラベル名",…], y=["y1列ラベル名", "y2列ラベル名",…])
散布図の主なキーワード引数としては、次のものがあります。
| 設定内容 | キーワード引数名 | 設定例 |
|---|---|---|
| プロットのサイズ | s |
数値:一括設定[リスト]など:プロット毎個別設定 |
| プロットの色 | c,( color, fcでもOK) |
色の名前やそのリストなど:
|
| カラーマップの指定 | cmap |
|
例として、次のような乱数データで散布図を作成してみましょう。
#乱数を25個ずつ生成
x = np.random.rand(25)
y = np.random.rand(25)
z = np.random.rand(25)
v = np.random.rand(25)
df = pd.DataFrame({"x":x, "y":y, "z":z, "v":v})
# x y z v
# 0 0.926029 0.381441 0.779438 0.569863
# 1 0.737767 0.732759 0.616394 0.545824
# 2 0.456538 0.213469 0.696929 0.157081
# ~省略~
# 24 0.046963 0.129599 0.348858 0.367356
デフォルト設定で散布図を作成してみます。
df.plot(kind="scatter", x="x", y="y")
次のようなデフォルト設定の散布図が作成されます。

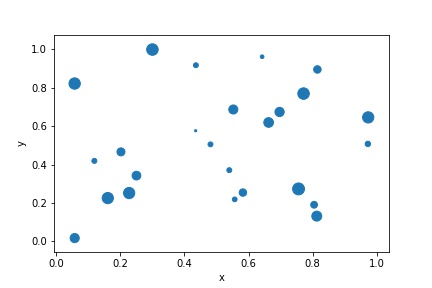
次に、各プロットの特徴量に応じてプロットサイズを変更する例を紹介します。
x列、y列と同じサイズのarray_likeをsに渡します。
df.plot(kind="scatter", x="x", y="y", s=150*df["z"])
DataFrameの場合は、df["列名"]としてSeriesで渡せばいいですね。
プロットの色を変更する場合は、fcに色を指定しましょう。
df.plot(kind="scatter", x=["x", "y"], y=["v", "z"], fc=["red", "blue"])
次のように色が変更されます。

特徴量に応じて色を変更する場合には、次のように設定します。
cmap="カラーマップ名"c=特徴量を表すarray_like(DataFrameの列など)
"カラーマップ名"はMatplotlibに組み込まれているものを指定します。
カラーマップを含めた色の指定については、次の記事を参照してください。
ここでは、例として次の2種類のカラーマップを指定してみましょう。
- 寒色系:
cmap="winter" - 暖色系:
cmap="spring"
サブプロットで並べて表示してみましょう。
fig, axes = plt.subplots(1,2, tight_layout=True)
df.plot(ax=axes[0], kind="scatter", x="x", y="y", c="z", s=150*df["v"], cmap="winter")
df.plot(ax=axes[1], kind="scatter", x="x", y="y", c="z", s=150*df["v"], cmap="spring")
次のように特徴量に応じて色付けされた散布図が作成されます。

散布図についての、より詳しい解説については次の記事を参考にしてみてください。

おわりに|padans関連おススメ追加コンテンツ
今回はpandasの.plot()について解説しました。
pandasは便利すぎて操作方法がわかりにくいことがよくあります…。
結局はコツコツ学ぶのが、pandasマスターの近道ですよね!≫【ブログカテゴリー:pandas】












