pandasで、excelファイルを読み込むための関数read_excel()について解説します。
read_excel()は、引数で読み込みの細かい設定が可能です:
- 表のデータがセルA1から始まっていないときの対応方法
indexやlabelの行や列を指定する方法- 読み込む行・列の指定
など、についても図解付きで解説していきます!
基本的な使用方法
read_excel()を使用すると、excelのデータからDataFrameを作成できます。
引数で細かい設定をできるのですが、まずは基本的な読み込み方法を確認してみましょう。
read_excel():excelファイルを読み込む
次のデータを持ったexcelファイルを例に基本的な読み込み操作を解説します。

read_excel()にexcelファイルのパスを与えると、excelのデータからDataFrameを作成します。
import pandas as pd
df = pd.read_excel("read_excel_example.xlsx")
print(df)
# Name apple orange banana
# 0 Gai 10 20 15
# 1 Mamoru 30 40 30
# 2 Hana 50 60 40
# 3 Mikoto 30 40 20
デフォルトでは、
- ヘッダーには、データの一行目が、
- インデックスには、自動で連番が
割り当てられます。
これを変更したい場合には、後述するheaderやindex_colなどを使用します。
また、ファイルのパスではなく、openで事前に開いたファイルを渡すことも可能です。
f = open("read_excel_example.xlsx", "rb")
df = pd.read_excel(f)
すでにファイルを開いている場合には、こちらが便利ですね。
sheet_name:読み込むシートの指定
デフォルトでは、excelファイルの初めのシートが読み込まれます。
別のシートを読み込みたい場合には、sheet_nameを指定します。
次の2つの方法で指定することができます。
- シート名を
文字列で入力 - シート番号を
intで入力
シート番号は、順番に0, 1, 2…となります(下図)。

上の図の例で2番目のシート「5月のデータ」を指定してみましょう。
まずは、シート名で指定します。
df = pd.read_excel("read_excel_example_.xlsx", sheet_name="5月のデータ")
次にシート番号で指定してみます。
df = pd.read_excel("read_excel_example_.xlsx", sheet_name=1)
シート番号は0から始まるので、2番目のシート番号は1ですね。
ヘッダー・インデックスの指定
デフォルトでは、
- ヘッダーには、データの一行目が、
- インデックスには、自動で連番が
割り当てられます。
ヘッダーやインデックス位置を調整したい場合は、header、index_colを使用します。
header:ヘッダー(列名)の行を指定
デフォルトでは、データの1行目がヘッダーとして扱われて、label名が設定されます。
headerを明示的に指定すると:
header = int⇒ ヘッダー行header = None⇒ ヘッダー行なし(自動で連番を振る)
を指定することができます。
次のようなデータを例にします。

headerを指定しない場合、0行目に余計なデータが入ります。
df = pd.read_excel("read_excel_example_.xlsx", header=0)
print(df)
# Name apple orange banana
# 0 名前 リンゴ オレンジ バナナ
# 1 Gai 10 20 15
# 2 Mamoru 30 40 30
# 3 Hana 50 60 40
# 4 Mikoto 30 40 100
headerを使用して、1行目をヘッダーに設定してみます。
df = pd.read_excel("read_excel_example_.xlsx", header=1)
print(df)
# 名前 リンゴ オレンジ バナナ
# 0 Gai 10 20 15
# 1 Mamoru 30 40 30
# 2 Hana 50 60 40
# 3 Mikoto 30 40 100
header=Noneとすると、ヘッダー行はないものとして扱われ、自動で連番が振られます。
df = pd.read_excel("read_excel_example_.xlsx", header=None)
print(df)
# 0 1 2 3
# 0 Name apple orange banana
# 1 名前 リンゴ オレンジ バナナ
# 2 Gai 10 20 15
# 3 Mamoru 30 40 30
# 4 Hana 50 60 40
# 5 Mikoto 30 40 100
names:列名を自分で設定
namesにリストなどを渡すと、label名を上書きできます。
次のデータでlabel名をnamseで別途指定してみます。
df = pd.read_excel("read_excel_example_.xlsx", names=["名前", "林檎", "オレンジ", "バナナ"])
print(df)
# 名前 林檎 オレンジ バナナ
# 0 Gai 10 20 15
# 1 Mamoru 30 40 30
# 2 Hana 50 60 40
# 3 Mikoto 30 40 100
ヘッダー行がない場合には
header = Noneを指定namesでlabel名を別途指定
します。
以下のヘッダーがないデータを考えます。
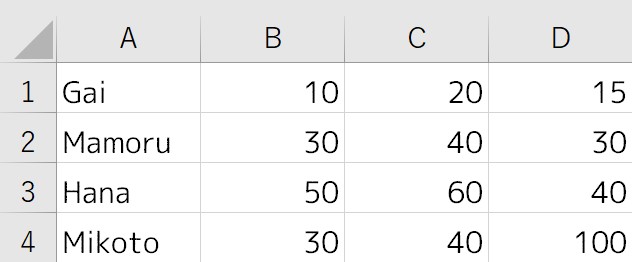
namesでlabel名を別途指定してみます。
df = pd.read_excel("read_excel_example_.xlsx", header = None, names=["名前", "林檎", "オ~レンジ", "バナ~ナ"])
print(df)
# 名前 林檎 オ~レンジ バナ~ナ
# 0 Gai 10 20 15
# 1 Mamoru 30 40 30
# 2 Hana 50 60 40
# 3 Mikoto 30 40 100
header = Noneを忘れないようにしましょう。
index_col:インデックス列の指定
デフォルトでは、インデックスには連番が振られます。
index_colを指定すると、指定した列をもとにindex名が振られます。
index_colは
- 列の番号
- 列のラベル名
のいずれかで指定することができます。
次のデータを例に、index_colを指定してみます。
"Name"の列をインデックスに指定してみます。
# 列番号で指定
df = pd.read_excel("read_excel_example_.xlsx", index_col=0)
print(df)
# apple orange banana
# Name
# Gai 10 20 15
# Mamoru 30 40 30
# Hana 50 60 40
# Mikoto 30 40 100
# ラベル名で指定
df = pd.read_excel("read_excel_example_.xlsx", index_col="Name")
print(df)
# apple orange banana
# Name
# Gai 10 20 15
# Mamoru 30 40 30
# Hana 50 60 40
# Mikoto 30 40 100
"Name"の列をインデックスに指定できました。
読み込む行・列の指定
excelのデータでは、必要なデータの上下左右に余計な情報が含まれていることが多々あります。
read_excel()では、
- 行をスキップ:skiprows, skip_footer
- 読み込む列を指定:usecols
することで、必要なデータのみを読み込むことができます。
以下のように、データがA1から始まっていない例を使用して解説していきます。
しかもこの例では、データの下部に余計なコメントまであります。

skiprows, skipfooter:上下の数行を読み飛ばす
それぞれintを指定すると、読み飛ばす行数を指定できます。
skiprows:上部の何行を読み飛ばすか指定skipfooter:データ下部の何行を読み飛ばすか指定

上下3行ずつ読み飛ばしてみましょう。
df = pd.read_excel("read_excel_example_.xlsx", skiprows=3, skipfooter=3)
print(df)
# Unnamed: 0 Name apple orange banana
# 0 NaN Gai 10 20 15
# 1 NaN Mamoru 30 40 30
# 2 NaN Hana 50 60 40
# 3 NaN Mikoto 30 40 100
上下の余計な入力内容を読み飛ばすことができました。
usecols:読み込む列を指定
列番号のリストや、列名を与えて読み込む列を指定することができます。
usecol = [ 1, 2, 5 ]⇒ 読み込む列番号をintで指定usecol = "A, C:D"⇒ 読み込む列名を文字列で指定
列名を文字列で与える場合には、リストではなく単体の文字列として与える点に注意しましょう!
- NG:
usecol = ["A", "C:D"] - OK:
usecol = "A, C:D"

上図のように、B:Eを読み込んでみます。
df = pd.read_excel("read_excel_example_.xlsx", skiprows=3, skipfooter=3, usecols="B:E")
print(df)
# Name apple orange banana
# 0 Gai 10 20 15
# 1 Mamoru 30 40 30
# 2 Hana 50 60 40
# 3 Mikoto 30 40 100
skiprows、skipfooter、usecolsを組み合わせて、必要なデータを抽出することができました。
おわりに
pandasで、excelファイルを読み込むための関数read_excel()について解説しました。
read_excel()は引数で読み込みの細かい設定が可能sheet_name:読み込むシートの指定haeder,index_col:ヘッダー行やインデックス列の指定skiprows,skipfooter,usecols:読み込む行・列の指定
こういった内容は、実際に手を動かしながら演習すると自然と身につくと思います。
実務でデータを取り扱っている方はそれを使用しながら、取り扱っていない方はデータ分析の参考書を使用しながら勉強されるのがおススメです。
私の場合は、両方で勉強していましたが、参考書としては特に次のものがおススメでした。
この参考書のレビューも書いてみました!
Twitter@YutaKaでは、ほぼ毎日pythonに関する情報を発信しています。
気楽にツイートしているので、気軽にフォローしてください!