pandasのDataFrameを使うと、行と列で構成されたデータを簡単に取り扱うことができます。
しかし、pandasの慣れないうちは、DataFrameの簡単な操作でつまずいてしまうことも…
例えば…
DataFrameの特定の行、列のデータを抽出するにはどうしたらいいの?df[ ]とかdf.loc[ ]とかdf.iloc[ ]とかいっぱいありすぎ!意味不明!
そこで、この記事では次の内容をわかりやすい図解付きで解説していきます:
DataFrameの特定の行、列のデータを抽出する方法- インデックス参照
[ ]、.loc[ ]、.iloc[ ]、at[ ]、iat[ ]の使い分け - ラベル名と行・列番号が混在したときのデータ抽出方法
DataFrameの行、列へのアクセス、抽出は、pandasを自由に操作するための第一歩です!
サクッと覚えて、pandasマスターを目指しましょう!
- DataFrameの基本構造
- DataFrameの行、列、値を抽出する方法
- ①インデックス参照で行、列抽出|df[ ]
- ②インデックス名、カラム名で行、列抽出|df.loc[ ]
- ③行番号、列番号で行、列抽出|df.iloc[ ]
- ④特定の値を抽出|at[ ], iat[ ]
- 【トラブル事例】ラベル名と行・列番号が混在するときの対処
- オススメ|pandasとデータ分析の勉強方法
DataFrameの基本構造
特定の行や列、値を抽出する場合には、DataFrameの次の要素を指定します。
- 行の指定:インデックス名または行番号
- 列の指定:カラム名または列番号
行は横方向、列は縦方向ですね。

まずは、DataFrameのどこがインデックスとカラム何に相当するのか整理しましょう。
インデックスとカラムは、それぞれ行・列を特定するラベルです(インデックス名とカラム名の2つをあわせてラベル名と呼ぶことにします)。

例えば、下図のようにインデックス名やカラム名を指定すれば、どの行、列を指定したのかがわかりますね。

インデックス名とカラム名を使えばデータの抽出ができそうですね(⇒df[ ], .loc[ ], .at[ ]で可能)。
また、各行や列は、ラベル名とは別に0から始まる行番号、列番号を持っています。

行番号、列番号を使ってもデータの抽出ができそうですね(⇒.iloc[ ], .iat[ ]で可能)。

ラベル名、行・列番号がDataFrameのどこに対応するかわかりました。
以下では、実際にこれらを使用してDataFrameのデータを抽出する方法を紹介します。
また、DataFrameにインデックス行やカラム列を設定する方法については、次の記事でわかりやすく解説しています。

DataFrameの行、列、値を抽出する方法
以下では、DataFrameの行、列、特定の値を抽出する方法を次の順番で紹介します。
- インデックス参照で行、列抽出|
df[ ] - インデックス名、カラム名で行、列抽出|
df.loc[ ] - 行番号、列番号で行、列抽出|
df.iloc[ ] - 特定の値を抽出|
at[ ],iat[ ]
実際には、df.loc[ ]とdf.iloc[ ]だけで、ほとんどの状況に対応できます。
しかし、それぞれの方法にメリットがあるので、他の手法もぜひチェックしてください!
以下では、次のDataFrameを例に各方法を紹介していきます。
data = {"Data0":[0,1,2],
"Data1":[10, 11, 12],
"Data2":[20, 21, 22], }
df = pd.DataFrame(data, index = pd.Index(["Ind0", "Ind1", "Ind2"], name="Ind"))

①インデックス参照で行、列抽出|df[ ]
pythonのリストや辞書型にアクセスするのと同じような方法です。
DataFrameの後ろに[ ]を付けて行、列を抽出します。
[ ]へのラベルの与え方によって、次の3つの使い方があります。
図解すると下図のようになります。
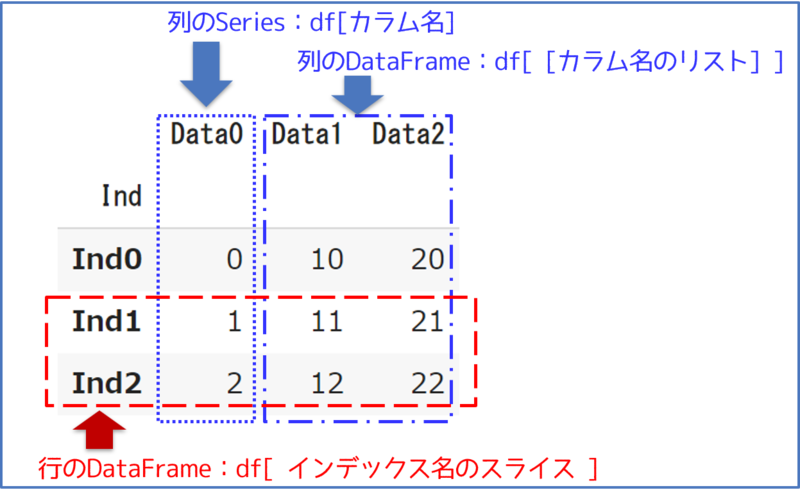
①:列のSeries|df[カラム名]
df[カラム名]で、dfの列をSeriesとして抽出できます。
df["Data0"]
# Ind
# Ind0 0
# Ind1 1
# Ind2 2
# Name: Data0, dtype: int64
"Data0"行がSeriesとして抽出されましたね。
このように列の抽出の場合には、インデックス参照が手軽で便利です。
②:列のDataFrame |df[ [カラム名のリスト] ]
複数列のDataFrameを抽出したい場合には、df[ [カラム名のリスト] ]で抽出します。
df[["Data1", "Data2"]]

[カラム名のリスト]は、1要素でもOKです。
df[ ["Data0"] ]

③:行のDataFrame|df[ :インデックス名のスライス ]
インデックス名のスライスを渡すと、スライス範囲の行がDataFrameとして抽出されます。
df["Ind1":"Ind2"]

このとき注意ですが、カラム名ではスライスはできません。
正直言うと、インデックス名、カラム名どちらで参照しているのかわかりにくいので、③はおススメできません。
インデックス名を指定する場合は、次に紹介するdf.loc[ ]の方がおススメです。
②インデックス名、カラム名で行、列抽出|df.loc[ ]
df.loc[ ]を使用すると、インデック名、カラム名でデータを抽出することができます。
抽出範囲は、インデックス、カラムの順に指定します。
df.loc[インデックス指定, カラム指定]
インデックス、ラベルの指定方法には主に次の3つを使用します。
単独のラベル名[ラベル名のリスト]:ラベル名のスライス
これらを組み合わせて、特定の位置のデータや選択範囲の行・列を抽出することができます。
行と列の指定方法と出力形式の関係を整理すると次の表のようになります。
| df.loc[インデックス指定, カラム指定] | カラム名(単体) |
[カラム名のリスト] or カラム名のスライス |
インデックス名(単体) |
①特定の位置のデータ | ②特定の列のSeries |
[インデックス名のリスト] orインデックス名のスライス |
②特定の行のSeries |
③選択範囲のDataFrame |
以下では、次の順番で抽出方法を解説していきます。
- 特定の位置のデータ
- 特定の行または列の
Series - 選択範囲の
DataFrame
特定の位置のデータを抽出
インデックス名、カラム名両方を指定すると特定の位置のデータが指定されます。
df.loc[インデックス名, カラム名]
サンプルデータで確認してみましょう。
df.loc["Ind1", "Data2"]
# 21
値を代入することで、書き込みも可能です。
df.loc["Ind1", "Data2"] = 999
# Data0 Data1 Data2
# Ind
# Ind0 0 10 20
# Ind1 1 11 999 ←値が書き換えられた。
# Ind2 2 12 2
特定の値にアクセス場合には、後述するdf.at[ ]でも可能です。
df.at[ ]の方が速いので、特定の値にアクセスするだけなら、df.at[ ]の方が良さそうです。
df.loc[ ]は、以下で説明するように行や列の抽出時に真価を発揮します。
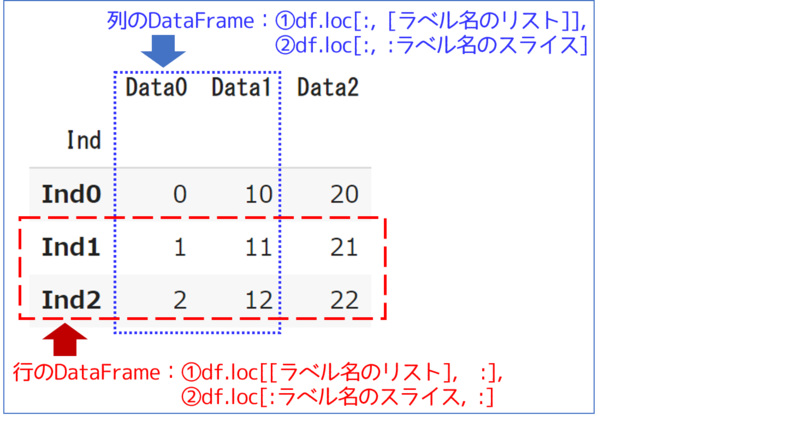
特定の行または列を抽出
特定の一行または列を指定する場合には、ラベル名指定とスライスを組み合わせます。
- 特定の行を指定|
df.loc[インデックス名, : ]またはdf.loc[インデックス名] - 特定の列を指定|
df.loc[:, カラム名]
下図のように対応した行、列がSeriesとして抽出されます。

サンプルコードをみて見ましょう。
# 行の抽出例
df.loc["Ind0", :] # またはdf.loc["Ind0"]
# ↓出力:Ind0行のシリーズ
# Data0 0
# Data1 10
# Data2 20
# Name: Ind0, dtype: int64
# 列の抽出例
df.loc[:,"Data0"]
# ↓出力:Data0列のシリーズ
# Ind
# Ind0 0
# Ind1 1
# Ind2 2
# Name: Data0, dtype: int64
一行または一列をDataFrameで出力したい場合には、要素が一つのリストとしてラベル名を渡します。
- 特定の行を指定|
df.loc[[インデックス名], : ]またはdf.loc[[インデックス名]] - 特定の列を指定|
df.loc[:, [カラム名]]
例として行を抽出してみましょう。
df.loc[["Ind0"], :]

これは次に紹介する複数行・列で、要素が一つのリストを渡したと考えると覚えやすいです。
複数の行または列を抽出
複数の行または列を指定する場合には、ラベル名を次のように指定します。
[ラベル名のリスト]:ラベル名のスライス
行、列の一方を : にすれば、特定の行、列の抽出が可能です。
例えば、[ラベル名のリスト]で指定する場合には、次のように指定します。
- 複数の行を抽出|
df.loc[[インデックス名のリスト], :]
またはdf.loc[[インデックス名のリスト]] - 複数の列を抽出|
df.loc[:, [カラム名のリスト]]
スライスの場合もまとめると下図のようになります。
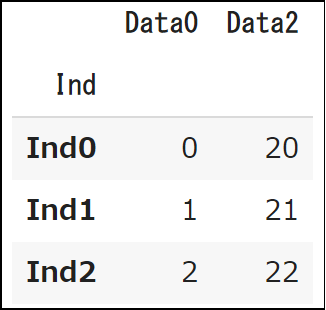
実際に行、列を抽出するサンプルコードを見てみましょう。
df.loc[["Ind0", "Ind1"], :]

次に列の抽出例を見てみましょう。
df.loc[:, ["Data0", "Data2"]]
とても簡単ですね。
もちろん、下図のように行および列を同時に指定して、DataFrameの一部を抽出することも可能です。

このとき、行または列の一方がラベル名だとシリーズとして抽出されます。
df.loc[["Ind0", "Ind1"], "Data0"]
# Ind
# Ind0 0
# Ind1 1
# Name: Data0, dtype: int64
行と列両方をリストで指定していると、DataFrameとして抽出されます。
df.loc[["Ind0", "Ind1"], ["Data0", "Data1"]]

ここまで理解すると、DataFrameへのアクセスが良くわかってきたと思います。
よりハイレベルを目指すのであれば、次のような書籍もおススメです

③行番号、列番号で行、列抽出|df.iloc[ ]
df.iloc[ ]を使用すると、行番号や列番号で行や列の抽出を行うことができます。
DataFrameの行、列には0から始まる行番号、列番が割り当てられています。
抽出範囲は、行番号、列番号の順に指定します。
df.loc[行番号指定, 列番号指定]
行番号、列番号の指定方法には主に次の3つを使用します。
単独の行番号・列番号:行番号・列番号のスライス[行番号・列番号のリスト]
これらを組み合わせて、特定の位置のデータや選択範囲の行・列を抽出することができます。
行と列の指定方法と出力形式の関係を整理すると次の表のようになります。
| df.loc[行番号指定, 列番号指定] | 列番号(単体) |
[列番号のリスト] or列番号のスライス |
| 行番号(単体) | ①特定の位置のデータ | ②特定の列のSeries |
[行番号のリスト] or行番号のスライス |
②特定の行のSeries |
③選択範囲のDataFrame |
以下では、次の順番で抽出方法を解説していきます。
- 特定の位置のデータ
- 特定の行または列の
Series - 選択範囲の
DataFrame
特定の位置のデータを抽出
行番号、列番号両方を指定すると特定の位置のデータが指定されます。
df.loc[行番号, 列番号]
特定の位置のデータにアクセスする例を紹介します。
df.iloc[1,2]
# 21
特定の値にアクセス場合には、後述するdf.iat[ ]の方が速いです。
特定の行または列を抽出
特定の一行または列を指定する場合には、ラベル名指定とスライスを組み合わせます。
- 特定の行を指定|
df.iloc[行番号, : ]またはdf.iloc[行番号] - 特定の列を指定|
df.iloc[:, 列番号]
下図のように対応した行、列がSeriesとして抽出されます。

サンプルコードをみて見ましょう。
# 行の抽出例
df.iloc[0, :] # またはdf.iloc[0]
# ↓出力:Ind0行のシリーズ
# Data0 0
# Data1 10
# Data2 20
# Name: Ind0, dtype: int64
# 列の抽出例
df.iloc[:,0]
# ↓出力:Data0列のシリーズ
# Ind
# Ind0 0
# Ind1 1
# Ind2 2
# Name: Data0, dtype: int64
一行または一列のDataFrameで出力したい場合には、要素が一つのリストでラベル名を渡します。
df.iloc[[0], :]
複数の行または列を抽出
複数の行または列を指定する場合には、ラベル名を次のように指定します。
: 行・列番号のスライス[行・列番号のリスト]
行、列の一方を : にすれば、特定の行、列の抽出が可能です。
例えば、行・列番号のスライスで指定する場合には、次のように指定します。
- 複数の行を抽出|
df.iloc[行番号のスライス, :]またはdf.iloc[行番号のスライス] - 複数の列を抽出|
df.iloc[:, 列番号のスライス]
[行・列番号のリスト]の場合もまとめると下図のようになります。

実際に行、列を抽出するサンプルコードを見てみましょう。
df.iloc[:2, :]
次に列の抽出例を見てみましょう。
df.iloc[:, 1:]

行と列両方を指定すると例を見てみましょう。
df.iloc[:2, 1:]

④特定の値を抽出|at[ ], iat[ ]
df.at[ ]やdf.iat[ ]を使用するとDataFrameの特定の位置のデータにアクセスすることができます。
df.at[インデックス名, カラム名]df.iat[行番号, 列番号]
df.loc[ ], df.iloc[ ]と違って、範囲指定ができない分df.at[ ], df.iat[ ]の方が速いです。
サンプルコードを紹介します。
df.at["Ind0", "Data1"]
# 10
df.iat[0, 2]
# 20
【トラブル事例】ラベル名と行・列番号が混在するときの対処
ここでは、DataFrameのdf.index属性とdf.columns属性を使用した対処方法を紹介します。
行・列番号とインデックス名、カラム名が混在している場合には次のように指定します。
df.loc[ df.index[行番号指定], カラムの指定 ]df.loc[インデックスの指定, df.columns[列番号指定] ]
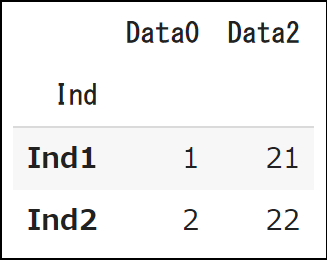
行番号とカラム名でデータを抽出する例をみてみましょう。
df.loc[df.index[1:], ["Data0", "Data2"]]
逆に列番号とインデックス名でデータを抽出する例をみてみましょう。
df.loc[["Ind0", "Ind1"], df.columns[:2]]
df.indexとdf.columnsの操作ができると、こういったDataFrameの細かい操作ができるようになってきます。
次の記事で詳しく解説しています。

こういった具体的な処理については、とにかく経験を積むしかないと思います。効率的に学びたい場合は。次のような書籍で実践に近い学習を積むのも一つの手だと思います。

オススメ|pandasとデータ分析の勉強方法
今回は、pandasのDataFrameをExcelに出力する方法について解説しました。
pandasは便利すぎて操作方法がわかりにくいことがよくあります…。
結局はコツコツ学ぶのが、pandasマスターの近道ですよね!
データ分析初心者の方にはこちらの記事もおススメです。
私がこれまで勉強してきた経験をもとに考えたおススメの勉強本の紹介記事です。
何から始めて、どうやってレベルアップしていけばいいのか、初心者の方にぜひおススメしたい本を紹介しました。

オススメのpandas本については、次の記事で紹介しています。