pandasのDataFrameでは、インデックス名やカラム名を使ってデータにアクセスしますね。
そのため、pandasを自由に扱うためには、インデックスやカラムの操作は重要なスキルです!
とは言っても、pandasの操作に慣れていないうちは、ちょっとした操作も難しいですよね。
例えば、次のようなことで悩んでしまうことも:
- どうやってインデックスやカラムを設定するの?
- インデックスやカラム名を変更する方法は?
そこで、この記事では次の内容をサンプルコード付きで解説していきます:
- インデックスの基本的な設定方法、変更方法
- インデックス番号のリセット方法
インデックス関係の処理をマスターして、自由にpandasを操作できるようになりましょう!
インデックス・カラムの設定方法
インデックス、カラムの設定方法について様々なケースを紹介します。
pd.DataFrame()の引き数で設定- 辞書型から
DataFrame生成時のラベル設定 - Excel、CSVデータ読み込み時に指定
pd.DataFrame()の引き数で設定|index, columns
pd.DataFrame()を使用すると、リストなどArray-likeをもとにDataFrameを作成できます。
このとき引数で、インデックスやカラムも同時に設定できます。
index:[インデックス名のリスト]などcolumns:[カラム名のリスト]など
意識して覚えたいのが、引数名のindexは単数なのに、columnsは複数なのです。
リストでインデックス名、カラム名を設定する例を紹介します。
data_list =[[10, 11],
[100, 101],
[1000, 1001]]
df = pd.DataFrame(data_list,
columns=["Col0", "Col1"],
index=["Ind0", "Ind1", "Ind2"] )

[リスト]からDataFrameを生成する方法はこちらの記事を参考にしてください。

辞書型からDataFrame生成時のラベル設定
辞書型をpd.DataFrame()に渡すと次のようにDataFrameが作成されます。
辞書のkey:DataFrameのカラム名辞書のvalues:DataFrameの値
d = {'Col0':[0, 1],
'Col1': [11, 12],
'Col2': [20, 21]}
df = pd.DataFrame(d)

次のようなネスト構造の辞書型だと、カラム名だけでなくインデックス名も設定されます。
{key_a: {key0: value0, key1: value1}}
外側と内側のキーをもとにカラムとインデックスが設定されます。
d = {"col0":{"ind0": 0, "ind1":1},
"col1":{"ind0": 10, "ind1":11}}
df = pd.DataFrame(data=d)

辞書型のインデックス設定の詳しい解説は、次の記事を参考にしてください。

Excel、CSVデータ読み込み時に指定
pandasでExcel、CSVを読み込むときは、それぞれ次の関数を使います。
- Excelファイルの読み込み:
pd.read_excel(フォルダパス) - CSVファイルの読み込み:
pd.read_csv(フォルダパス)
いずれの関数でも共通の引数で、ヘッダー行(カラム行)、インデックス行を指定します。
- カラム:
header = ヘッダーの行番号 - インデックス:
index_col = インデックスの列番号or"列名"
ここでは、次のExcelファイルでヘッダー行、インデックス行を指定してみましょう。

df = pd.read_excel("read_excel_example.xlsx", header=0, index_col=0) # header=0は省略可能
print(df)
# Name apple orange banana
# Gai 10 20 15
# Mamoru 30 40 30
# Hana 50 60 40
# Mikoto 30 40 20
read_excel(), read_csv()の詳しい解説はそれぞれ次の記事を参考にしてください。


生成後のdfのインデックス名、カラム名の変更
生成後のDataFrameにインデックス名やカラム名を設定、一部を変更する方法を紹介します。
- dfのプロパティでラベル名設定①|
df.index=[…] - dfのメソッドでラベル名設定②|
df.axis() - ラベル名を一部変更|
df.rename() - カラム名の前後に文字列追加|
df.prefix (),df.suffix()
既存dfにラベル名を設定①|df.index=[…]
既存dfのindex属性、columns属性を書き換えると、インデックス、カラムを設定・上書きできます。
df.index = [インデックス名]などdf.columns = [カラム名]など
次のDataFrameを例にインデックス、カラムを設定してみます。
data = [[0, 1, 2],
[10, 11, 12]]
df = pd.DataFrame(data)

インデックス名、カラム名を設定してみます。
df.index=["i0", "i1"]
df.columns=["c0", "c1", "c2"]

既存dfにラベル名を設定②|df.axis()
既存DataFrameのインデックス、カラムを設定・上書きは、df.set_axis()メソッドでも可能です。
df.set_axis()|dfのインデックス、カラム名の設定
| 引数名 | 型 | 説明 |
|---|---|---|
labels |
[リスト]やpd.Indexなど |
設定するラベル名 ⇒ axisで指定した箇所に設定される |
axis |
数値(0, 1) or str("index", "columns") |
"index"or0:インデックス名を指定"columns" or 1:カラム名を指定 |
inplace |
True or False |
True:dfそのものを上書きFalse(デフォルト):新しいdfを返す(元のdfは変化なし) |
例えば、既存のdfのインデックス名・カラム名を設定、上書きする場合には次のように書きます。
- インデックス設定:
df.set_axis([インデックス名], axis="index", inplace=True) - カラム設定:
df.set_axis([カラム名], axis="columns", inplace=True)
次のDataFrameを例にインデックス、カラムを設定してみます。
data = [[0, 1, 2],
[10, 11, 12]]
df = pd.DataFrame(data)

インデックス名、カラム名を設定してみます。
df.set_axis(["i0", "i1"], axis="index", inplace=True)
df.set_axis(["c0", "c1", "c2"], axis="columns", inplace=True)
結果はdf.index, df.columnsの書き換えと同じですね。
列をインデックスに指定|df.set_index()
DataFrameのメソッド、df.set_index()で既存の列を指定してインデックス行に設定できます。
次のDataFrameの"ind"列をインデックス行に指定しています。
data = [["i0", 0, 1, 2],
["i1", 10, 11, 12]]
df = pd.DataFrame(data, columns=["ind", "c0", "c1", "c2"])

"ind"列をインデックス行に指定します。
df.set_index("ind", inplace=True)

DataFrame生成時に、一行で次のように書いてもOKです。
df = pd.DataFrame(data, columns=["ind", "c0", "c1", "c2"]).set_index("ind", inplace=True)
同様の方法で、カラムを設定する方法は存在しないようです。
dfのラベル名を一部変更|df.rename()
既存dfのインデックス、カラムの一部を変更する場合には、df.set_axis()メソッドを使用します。
df.set_axis()の引数の与え方には、2種類あります。
index,columnsそれぞれに変更内容を与えるmapperに変更内容を与えて、axisで"index"と"columns"どちらかを指定
どちらの使い方でもOKですが、わかりやすいパターン1を解説します。
df.set_axis()|index,columnsに変更内容を与えるパターン
| 引数名 | 型 | 説明 |
|---|---|---|
index |
辞書型 または 関数 | ラベルの変更方法
|
columns |
辞書型 または 関数 | ラベルの変更方法
|
inplace |
True or False |
True:dfそのものを上書きFalse(デフォルト):新しいdfを返す(元のdfは変化なし) |
このとき変更パターンは辞書型または関数で次のように与えます。
- 辞書型:
{既存名1:新規名1, 既存名2:新規名2…} - 関数:
新規名 = f(既存名)となるような関数f
次のDataFrameを例に、それぞれの使用例を紹介します。
data = [[0, 1, 2],
[10, 11, 12],
[20, 21, 22]]
df = pd.DataFrame(data, index=["i0", "i1", "i2"], columns=["c0", "c1", "c2"])

まずは辞書型を使った書き換え例を見ていきましょう。
次の形式で入力した辞書型を使って、ラベル名を書き換えます。
{既存名1:新規名1, 既存名2:新規名2…}
インデックス名、カラム名を変更してみましょう。
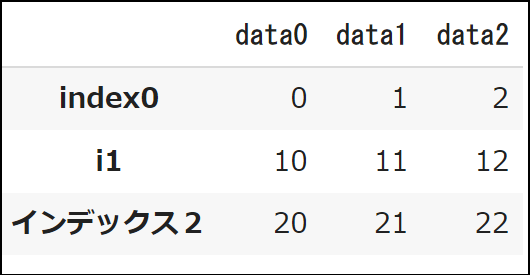
df.rename(index={"i0":"index0", "i2": "インデックス2"}
, columns={"c0":"data0", "c1": "data1", "c2":"data2"})
次に関数を適用するパターンを紹介します。
関数を適用する場合には、次のような関数fが既存ラベル名に適用されると考えましょう。
新規ラベル名 = f(既存ラベル名)
例として、文字列を大文字にする組み込み関数str.upper()を適用してみます。
df.rename(index=str.upper)

ラムダ関数との相性もいいです。
既存ラベル名の最後の一文字を抽出して、新規ラベルにする例を紹介します。
f = #関数を作成
df.rename(index= lambda s: int(s[-1]))

自分で作った関数を適用すれば、様々な応用ができそうですね。
ラベル名の前後に文字列追加|df.prefix (), df.suffix()
ラベル名の前後に文字列を追加する場合には、次のメソッドを使用します。
- ラベル名の前に追加|
df.prefix("ラベル前に置く文字列") - ラベル名の後に追加|
df.suffix("ラベル後に置く文字列")
df.add_prefix("New_")

df.add_suffix("_old")

これらのメソッドは、新しいDataFrameを返します。
dfを上書きしたい場合は、戻り値をdfで受けましょう。
df = df.add_prefix("New_") # dfを上書き
インデックスのリセット|df.reset_index()
DataFrameを結合したり、データの一部を削除したりすると、DataFrameのインデックス番号がズレることがよくあります。
そういった場合は、df.reset_index()でインデックス番号を振りなおすことができます。
df.reset_index()|インデックスの再設定
| 引数名 | 型 | 説明 |
|---|---|---|
drop |
True or False |
True:今のインデックスを列として残すFalse(デフォルト):今のインデックスは残さない |
inplace |
True or False |
True:dfそのものを上書きFalse(デフォルト):新しいdfを返す(元のdfは変化なし) |
DataFrameを結合してインデックス番号がズレてしまう例をみてみます。
data1 = [[0, 1],
[10, 11]]
df1 = pd.DataFrame(data1)
data2 = [[20, 21],
[30, 31]]
df2 = pd.DataFrame(data2)
df_c = pd.concat([df1, df2])

それぞれのdfのインデックスが結合されているので、ゴチャゴチャになっています。
df.reset_index()で再設定してみます。
df.reset_index()

デフォルトでは、既存のインデックスは列データとして残ります(上の例では"index"列)。
残したくない場合はdrop=Trueを指定します。
行を削除してインデックス番号がズレたケースを例に、drop=Trueの結果を見て見ましょう。
data = [[0, 1],
[10, 11],
[20, 21],
[30, 31]]
df = pd.DataFrame(data, columns=["c0", "c1"])
df.drop(1, inplace=True)

列を削除したので、インデックスが連番ではなくなっていますね。
df.reset_index()で再設定してみます。
df.reset_index(drop=True)

無事、連番に再設定されました。
おわりに|padans関連おススメ追加コンテンツ
今回はpandasのインデックスの設定、変更に関する内容を紹介しました。
pandasは便利すぎて操作方法がわかりにくいことがよくあります…。
結局はコツコツ学ぶのが、pandasマスターの近道ですよね!≫【ブログカテゴリー:pandas】



Twitter@YutaKaでは、ほぼ毎日pythonに関する情報を発信しています。
気楽にツイートしているので、気軽にフォローしてください!