pandasで、DataFrameやSeriesのデータを月ごと週ごとなどで集計する方法を解説します。
このような期間ごとのデータ集計を行う場合は、.resample()メソッドを使用します。
しかし、初めのうちは集計方法がわからず、次のような疑問に直面してしまうことも…。
- 集計期間はどうやって設定するの?
- 合計や平均などの集計方法はどうやって設定する?
- 自作関数の適用方法、列毎に違う集計をする方法はあるの?
そこで、今回は.resample()の使い方を、図解、サンプルコード付きでわかりやすく解説します。
月ごと、週ごとに集計|resample()の基本
DataFrame、Seriesを月ごと、週ごとなどで集計するには、.resample()メソッドを使用します。
.resample()メソッドの基本形は下図の通りです。

データ集計時のポイントは、次の2つを指定することです。
.resample()の引数で、集計期間を指定(月:"M", 週:"W"など).resample()に続くメソッドで、集計方法を指定(.sum(),.mean()など)
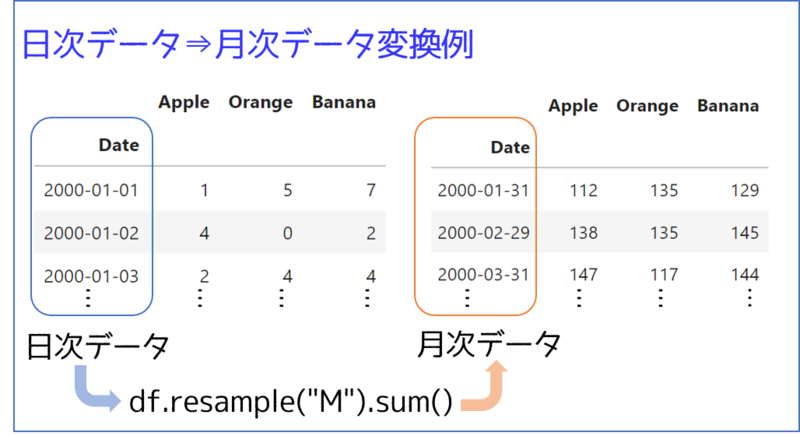
例えば、あるDataFrame, dfの月ごとの合計は、次のように集計します。
df.resample("M").sum()
すると、次のように月次集計されたDataFrameが生成されます。
以下では、まず集計期間指定と集計方法の概要を整理します。
- 集計期間の指定方法まとめ
- 集計方法まとめ
それぞれ使用頻度が高そうな内容について、詳細な解説も追加しています。
.resample()を使用する場合、インデックス行の日付が"文字列"ではなくDatetimeである必要があります。
"文字列"の日付をDatetimeに変更する方法を詳しく知りたい方は、次の記事を参考にしてください。

集計期間の指定方法まとめ|M, W, D…
集計期間は、"文字列"で渡す点に注意しましょう。
df.reample("集計期間").集計メソッド()
主な集計期間の設定方法は以下の通りです。
| 集計期間指定値 | 集計期間 | データの書き出し日 |
|---|---|---|
"M" |
月ごとに集計 | 各月の最終日 例)1月分⇒1月31日に出力 |
"MS" |
月ごとに集計 | 各月の初日 例)1月分⇒1月1日に出力 |
"Q" |
四半期ごとに集計 | 四半期初日 例)1Q⇒1月1日 |
"QS" |
四半期ごとに集計 | 四半期最終日 例)1Q⇒3月31日 |
"W" |
週ごとに集計 ※前の月曜日から日曜まで |
各週の日曜日の日にち |
"W-XXX"XXX: 3文字で曜日を指定 |
週ごとに集計 ※ XXX曜日の6日前からXXX曜日まで |
XXXで指定した曜日XXX = Sun, Mon, Tue, Wed, Thu, Fri, Sat |
"nD"n: 数字 |
n日間ごとに集計 |
各集計期間の初日 |
nDと同様に、nM、nWと指定することで、それぞれnヵ月、n週間の集計も可能です。
次のサンプルデータで、月ごと、週ごと、任意の日にちでの集計を詳しく解説していきます。
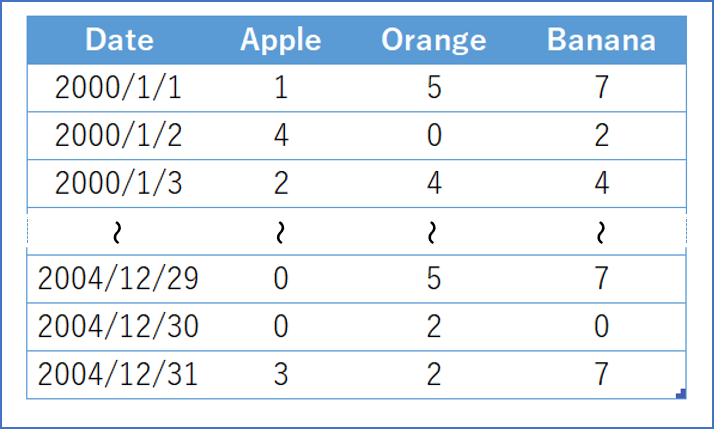
エクセルやCSVのデータの読み込み方法を詳しく知りたい方は、次の記事を参考にしてください。


月ごとに集計
月ごとに集計する場合には、集計期間を"M"または"MS"で指定します。
それぞれの挙動の違いは以下の通りです。
| 集計期間指定値 | 集計期間 | データの書き出し日 |
|---|---|---|
"M" |
月ごとに集計 | 各月の最終日 例)1月分⇒1月31日に出力 |
"MS" |
月ごとに集計 | 各月の初日 例)1月分⇒1月1日に出力 |
サンプルデータを使用して、出力結果を比較してみましょう。
df.resample("M").sum()
# Apple Orange Banana
# Date
# 2000-01-31 112 135 129
# 2000-02-29 138 135 145
# 2000-03-31 147 117 144
# 以下略
df.resample("MS").sum()
# Apple Orange Banana
# Date
# 2000-01-01 112 135 129
# 2000-02-01 138 135 145
# 2000-03-01 147 117 144
# 以下略
"M"の場合は月終わり、"MS"の場合は月初めの日がインデックスになっていますね。
月初め、月終わりどちらに集計結果を出力するかで、使い分けましょう。
また、整数nを先頭に加えて、"nMS"と指定すると、nヶ月ごとの集計も可能です。
df.resample("3MS").sum()
# Apple Orange Banana
# Date
# 2000-01-01 397 387 418
# 2000-04-01 409 396 388
# 2000-07-01 400 391 446
# 以下略
数か月ごとの集計に類似したもので、"Q"または"QS"指定で四半期ごとの集計も可能です。
df.resample('Q').sum()
# Apple Orange Banana
# Date
# 2000-03-31 397 387 418
# 2000-06-30 409 396 388
# 2000-09-30 400 391 446
# 以下略
df.resample('QS').sum()
# Apple Orange Banana
# Date
# 2000-01-01 397 387 418
# 2000-04-01 409 396 388
# 2000-07-01 400 391 446
# 以下略
四半期集計の場合も、"Q"は四半期終わりの日に、"QS"は四半期初めの日に出力するという違いがあります。
週ごとに集計
週ごとに集計する場合には、集計期間を"W"または"W-XXX"で指定します。
| 集計期間指定値 | 集計期間 | データの書き出し日 |
|---|---|---|
"W" |
週ごとに集計 ※月曜日から日曜日まで |
各週の日曜日の日にち |
"W-XXX"XXX: 3文字で曜日を指定 |
週ごとに集計 ※ XXX曜日の6日前から、XXX曜日まで |
XXXで指定した曜日XXX = Sun, Mon, Tue, Wed, Thu, Fri, Sat |
"W"は、下図のように前の月曜日から日曜日までのデータを集計して、日曜日に出力します。
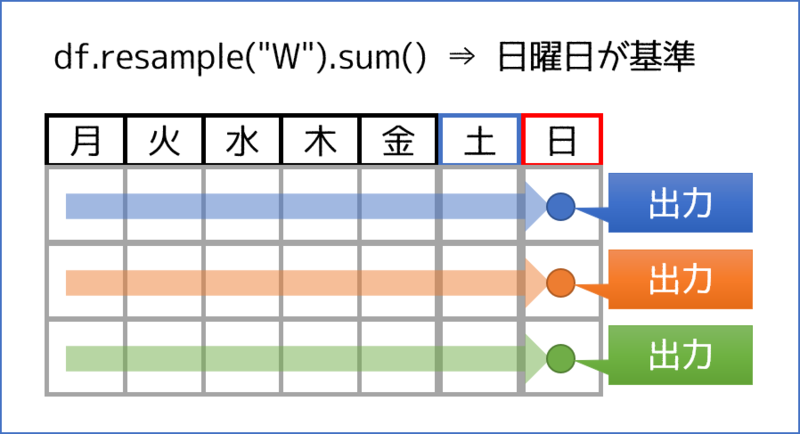
集計の基準を日曜日以外に変更する場合には、"W-XXX"で基準曜日を指定します。

サンプルデータを使用して、出力結果を比較してみましょう。
df.resample("W").sum()
# Apple Orange Banana
# Date
# 2000-01-02 5 5 9 # 2000-01-02は日曜日です。
# 2000-01-09 30 25 27
# 2000-01-16 19 30 25
# 以下略
df.resample("W-Wed").sum()
# Apple Orange Banana
# Date
# 2000-01-05 14 18 21 # 2000-01-02は水曜日です。
# 2000-01-12 29 30 33
# 2000-01-19 26 21 23
# 以下略
曜日を気にせずに、データの初日から7日ごとに集計したい場合は、次項のnDでn=7を指定します。
任意の日にちで集計
任意の日にちで集計する場合には、集計期間を"nD"で指定します。
| 集計期間指定値 | 集計期間 | データの書き出し日 |
|---|---|---|
"nD"n: 数字 |
n日間ごとに集計 |
各集計期間の初日 |
サンプルデータを使用して、n=7の出力結果をみてみましょう。
df.resample("7D").sum()
print(df.resample("7D").sum().head(3))
# Apple Orange Banana
# Date
# 2000-01-01 26 24 28
# 2000-01-08 19 29 30
# 2000-01-15 33 28 27
# 以下略
"nD"の場合には、各集計期間の初日に集計結果が出力される点に注意が必要です。
集計方法まとめ|sum(), mean()…
集計期間は、resample().XXX()のようにメソッドで指定します。
df.reample("集計期間").集計メソッド()
主な集計期間の設定方法は以下の通りです。
| 集計方法 | メソッド名 |
|---|---|
| 合計 | .sum() |
| 平均 | .mean() |
| 最大 | .max() |
| 最小 | .min() |
| 初期値 | .first() |
| 最終値 | .last() |
| 標準誤差 | .std() |
| 始値、高値、安値、終値 | .ohlc() |
任意の関数, func |
.apply(func)func:array_likeを引数にする関数 |
| 複数関数の適用、列ごとに異なる関数適用 | .agg()※使い方は後述 |
次のサンプルデータで、集計方法設定について解説していきます。
エクセルやCSVのデータの読み込み方法を詳しく知りたい方は、次の記事を参考にしてください。
基本的な集計|sum, mean…
基本的な集計例として、.sum(), .mean(), .ohlc()の集計例を見てみましょう。
df.resample("M").sum()
print(df.resample("M").sum().head(3))
# Apple Orange Banana
# Date
# 2000-01-31 112 135 129
# 2000-02-29 138 135 145
# 2000-03-31 147 117 144
# 以下略
df.resample("M").mean()
print(df.resample("M").mean().head(3))
# Apple Orange Banana
# Date
# 2000-01-31 3.612903 4.354839 4.161290
# 2000-02-29 4.758621 4.655172 5.000000
# 2000-03-31 4.741935 3.774194 4.645161
# 以下略
df.resample("M").ohlc()
print(df.resample("M").ohlc().head(3))
# Apple Orange Banana
# open high low close open high low close open high low close
# Date
# 2000-01-31 1 9 0 9 5 9 0 5 7 9 0 1
# 2000-02-29 9 9 0 0 4 9 0 6 3 9 0 6
# 2000-03-31 1 9 0 1 2 9 0 6 1 9 0 9
# 以下略
.ohlc()の場合は集計結果が複数なので、マルチインデックスになっていますね。
任意の関数で集計|apply()
.apply()メソッドを使用すると、任意の関数で集計できます。
df.resample("集計期間").apply(function)functionはarray_likeを引数にする関数|function( array_like )
例として、NumPyのnp.sum()関数を適用してみます。
import numpy as np
df.resample("M").apply(np.sum)
# Apple Orange Banana
# Date
# 2000-01-31 112 135 129
# 2000-02-29 138 135 145
# 2000-03-31 147 117 144
# 以下略
次に自作の関数, my_funcを適用する例を紹介します。
自作関数, my_funcは、引数がarray_likeとなるように作成します。
def my_func(array_like):
return (max(array_like) - min(array_like))
x = [2, 10, 3]
print(my_func(x))
# 8
この関数は、引数のarray_likeの最大値と最小値の差を計算する関数ですね。
この自作関数を.resample.apply()で適用してみましょう。
df.resample("7D").apply(my_func)
# Apple Orange Banana
# Date
# 2000-01-01 7 9 6
# 2000-01-08 6 6 7
# 2000-01-15 2 8 8
# 以下略
.apply()を使えば、自作関数での集計も簡単に実行できますね。
同時に複数の集計適用|.agg()
.agg()メソッドを使用すると、同時に複数の集計を適用できます。
引数として、集計名("max"など)または関数名(np.sumなど)のリストを渡します。
df.resample("7D").agg(['min', 'max', np.sum])
# Apple Orange Banana
# max sum max sum max sum
# Date
# 2000-01-01 7 26 9 24 7 28
# 2000-01-08 6 19 7 29 8 30
# 2000-01-15 6 33 8 28 8 27
# 以下略
集計結果が複数なので、マルチインデックスになっていますね。
列ごとに異なる集計適用|agg({列名:集計方法})
ある列は合計、ある列は平均を集計したい場合もあるかと思います。
.agg()メソッドを使用すると、列ごとに異なる集計をすることも可能です。
その場合、引数として{列名: 集計方法}を要素とする辞書を渡します。
df.resample("集計期間").agg({"列1": 集計方法1, "列2": 集計方法2, …})- 集計方法:集計名(
"max"など)、関数(np.sumなど)またはそれらのリスト
- 集計方法:集計名(
各列に異なる集計を適用した例をみて見ましょう。
df.resample("M").agg({"Apple":"sum", "Orange": max, "Banana":np.sum})
# Apple Orange Banana
# sum max sum
# Date
# 2000-01-31 112 9 129
# 2000-02-29 138 9 145
# 2000-03-31 147 9 144
# 以下略
各列に、価格だったり、個数だったり、単価だったり、いろいろなデータが混ざっているときの集計時に力を発揮しそうな機能ですね。
おわりに|padans関連おススメ追加コンテンツ
今回はpandasで月ごと週ごとの集計をする方法を解説しました。
pandasは便利すぎて操作方法がわかりにくいことがよくあります…。
結局はコツコツ学ぶのが、pandasマスターの近道ですよね!≫【ブログカテゴリー:pandas】









Twitter@YutaKaでは、ほぼ毎日pythonに関する情報を発信しています。
気楽にツイートしているので、気軽にフォローしてください!