pandasの.groupby()を使うと、DataFrameの要素をもとにデータをグループ分けして、簡単に集計することができます。
しかし、いざ.groupby()を適用とすると次のような疑問に直面することも…
.groupby()の使い方が難しくて、よくわからない!- グループ分け結果の確認方法はどうするの?
- 具体的にどうやってグループごとの集計するの?
そこで、今回は.groupby()を使って、グループ毎に集計する方法を図解、サンプルコード付きでわかりやすく解説していきます。
実例で見る!groupbyの使い方
pandasの.groupby()を使用すると、DataFrameの要素をもとにデータをグループ分けして、集計することができます。
まずは、サンプルデータを使って、groupby()の実行例を確認してみましょう。
次の例ではインデックス列の要素をもとにグループ分けして、グループ毎のData列の合計値を出力しています。
# サンプルDataFrameの用意
my_index = ["A", "B", "C", "A", "B", "A"]
my_data = {"Data1":[1,2,3,3,2,1], "Data2":[50,40,30,20,10,0]}
df = pd.DataFrame(my_data, index=pd.Index(my_index, name="Team"))
print(df)
# Data1 Data2
# Team
# A 1 50
# B 2 40
# C 3 30
# A 3 20
# B 2 10
# A 1 0
# groupbyによる集計例(グループごとに合計値計算)
df_grouped = df.groupby("Team").sum()
print(df_grouped)
# Data1 Data2
# Team
# A 5 70
# B 4 50
# C 3 30
簡単にグループごとの合計を計算できました。
と言っても、どんな処理をしたのかよくわからない!という方も多いかと思います。
そこでまずは、.groupby()の流れを図解していきます。
groupbyの流れをわかりやすく図解!
まずは.groupby()を実行した際の基本的な流れを解説していきます。
.groupby()は、次の3つのステップで構成されています。
- STEP①:グループ分け(split)
- STEP②:グループごとに関数適用(apply)
- STEP③:各グループの結果を一つに結合(combine)
これらの一連の流れを図解すると次のようになります。

この図では、①:"分類"列の値をもとにグループ分け、②:グループごとにsum関数を適用、③:結果を結合という流れで処理しています。
.groupby()のポイントは、次の2つをしっかりと理解することだと思います。
- ①グループ分け
- ②各グループへの関数適用
以下では、次の順番で.groupby()を解説していきます。
- グループ分け結果の確認・可視化方法
- グループ分け方法まとめ・詳細設定
- 関数の適用方法
groupbyのグループ分け結果の確認方法
.groupby()では、グループ分け結果の確認方法にややクセがあります。
グループ分け結果を自分で確認できないと、その先に進めないのでまずは結果の確認方法を覚えていきましょう。
まずは.groupby()よるグループ分け結果の中身を確認していきましょう。
.groupby()でDataFrameをグループ分けすると、グループ分け結果がGroupByオブジェクトとして生成されます。
g = df.groupby("CLASS")
print(type(g))
# <class 'pandas.core.groupby.generic.DataFrameGroupBy'>
print(g)
# <pandas.core.groupby.generic.DataFrameGroupBy object at 0x0000022F4637E7C8>
残念ながらGroupByオブジェクトをprint()関数で出力しても、グループ分け結果は出力されません。
多くの場合は、次のようにグループ分けの結果を確認したいものだと思います。
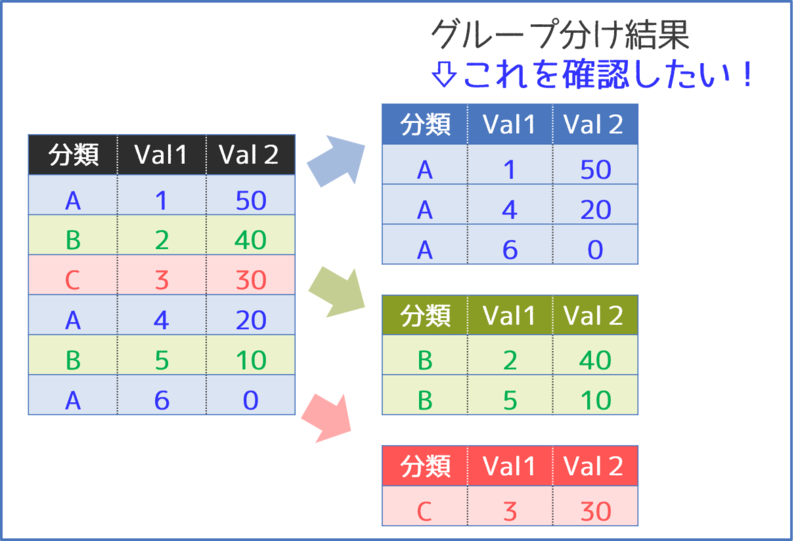
グループ分け確認方法の一覧表
次の表に、GroupByオブジェクト, gの中身を出力する方法の一覧を整理しています。
| 確認したい内容 | プロパティやメソッドなど | 出力形式 |
|---|---|---|
| グループ分け結果一覧 | g.groups |
辞書型{"グループ名": [グループ要素のインデックス], …} |
| グループ名一覧 | list(g.groups.key)[*g.groups] |
[グループ名のリスト] |
| グループ数 | len(g.groups) |
グループの個数(整数値) |
| グループ内要素数 | g.size() |
要素数のSeries |
| グループ内要素の種類の個数 (重複無しカウント) |
g.nuniqu() |
要素の種類の個数を整理したDataFrame |
| 特定のグループ抽出 | g.get_group("グループ名") |
特定のグループを抽出したDataFrame |
| 【応用】結果を見やすく可視化 | g.apply(print)g.apply(lambda a: a[:]) |
①画面への出力 ② DataFrameとして出力 |
次のサンプルデータを使用して、それぞれの内容を詳しく見ていきましょう。
my_data = {"Team":["A", "B", "C", "A", "B", "A"],
"Data1":[1,2,3,3,2,1],
"Data2":[50,40,30,20,10,0]}
df = pd.DataFrame(my_data)
# Data1 Data2
# Team
# A 1 50
# B 2 40
# C 3 30
# A 3 20
# B 2 10
# A 1 0
グループ分け一覧・グループ名/数・要素数|groups
GroupByオブジェクトのgroupsプロパティを参照して、グループ分け結果を一覧で確認できます。
groupsは結果を辞書型で返すため、keyや len()を利用して、グループ名、グループ数を取得することが可能です。
g.groups→{"グループ名1": [要素1, 要素2…], "グループ名2": [要素1, 要素2…]}list(g.groups.keys())or[*g.groups]→["グループ名1", "グループ名2"…]len(g.groups)→ グループ数
それぞれの出力結果を確認してみましょう。
# グループ分け結果一覧
df.groupby("Team").groups
# {'A': Int64Index([0, 3, 5], dtype='int64'),
# 'B': Int64Index([1, 4], dtype='int64'),
# 'C': Int64Index([2], dtype='int64')}
# グループ名一覧
list(df.groupby("Team").groups.keys())
# ['A', 'B', 'C']
[*df.groupby("Team").groups]
# ['A', 'B', 'C']
# グループ数
len(df.groupby("Team").groups)
# 3
辞書型の特徴を活かすことで、簡単にグループ分け情報が参照できますね。
次に、グループ内の要素数、要素の種類の数を確認する方法を紹介します。
g.size()→ グループごとの要素の個数g.nuniqu()→ 要素の種類の数(要素を重複なしでカウント)
# グループ内要素の個数
df.groupby("Team").size()
# Team
# A 3
# B 2
# C 1
# dtype: int64
# グループ内要素の種類の数(重複なしカウント)
df.groupby("Team").nunique()
# Team Data1 Data2
# Team
# A 1 2 3
# B 1 1 2
# C 1 1 1
要素数は"Data1"列、"Data2"列で共通ですが、要素の種類の数はデータの重複数に依存するので列毎に異なっていますね。
特定のグループ抽出|.get_group("グループ名")
.get_group()メソッドを使用すると、特定のグループの内容を抽出することができます。
.get_group("グループ名")→"グループ名"を抽出したDataFrameを生成
サンプルコードで挙動を確認してみましょう。
df_a = df.groupby("Team").get_group("A")
print(df_a)
# Team Data1 Data2
# 0 A 1 50
# 3 A 3 20
# 5 A 1 0
df_b = df.groupby("Team").get_group("B")
print(df_b)
# Team Data1 Data2
# 1 B 2 40
# 4 B 2 10
df_c = df.groupby("Team").get_group("C")
print(df_c)
# Team Data1 Data2
# 2 C 3 30
グループ毎にDataFrameを抽出することができましたね。
for文で、全てのグループの結果を抽出/確認することもできそうですね。
しかし、次に紹介する方法を使えばfor文なしで、全てのグループを確認できます!
【応用編】見やすく可視化方法
より見やすい形でグループ分け結果を可視化する方法を紹介します。
後述する.apply()メソッドを応用すると、グループ分け結果を見やすく可視化できます。
.apply(print)→ 画面(コンソール)への出力.apply(a: a[:])→ グループ分け結果のDataFrameを返す
サンプルデータをもとに出力例を見てみましょう。
df.groupby("Team").apply(print)
# Team Data1 Data2
# 0 A 1 50
# 3 A 3 20
# 5 A 1 0
# Team Data1 Data2
# 1 B 2 40
# 4 B 2 10
# Team Data1 Data2
# 2 C 3 30
# .apply(a: a[:])の例
df_visualized = df.groupby("Team").apply(lambda a: a[:])
print(df_visualized)
# Team Data1 Data2
# Team
# A 0 A 1 50
# 3 A 3 20
# 5 A 1 0
# B 1 B 2 40
# 4 B 2 10
# C 2 C 3 30
.apply()を使えば、手軽にグループ分け結果を確認できますね。
この方法は、以下のフォーラムを参考にしています。
これで.groupby()のグループ分け結果確認がある程度できるようになったかと思います。
次は、グループ分けの方法について詳しく解説します。
グループ分け方法まとめ
グループ分けの最も基本的な方法は、.groupby("列名")で"列名"を指定する方法です。
他にも、データ列ではなくindex列を使用したり、複数列を指定したりする方法もあります。
使用頻度が高そうなグループ分け方法を次の表にまとめています。
| グループ分け方法 | 指定方法 | コメント |
|---|---|---|
| 列の要素 | .groupby(by="列名") |
by=は省略可能 |
| 複数列の要素 | .groupby(by=["列名1", "列名2"…]) |
by=は省略可能列名1、2でマルチインデックス集計 |
| インデックスの要素 | .groupby(level=0) .groupby(by="インデックス名") |
by=は省略可能 |
| マルチインデックス | .groupby(level=[i, j…]).groupby(by=["インデックス名1",…]) |
i=0が一番外側のインデックスに対応by=は省略可能 |
| 関数適用でグループ分け | .groupby(by=func) |
func: グループの割り振りを返す関数(詳細は後述) |
次のDataFrameを例にそれぞれの挙動を見てみましょう。
my_data = {"Team":["A", "B", "C", "A", "B", "A"],
"Genre":["alpha", "alpha", "alpha", "beta", "beta", "beta"],
"Data1":[1,2,3,3,2,1], "Data2":[50,40,30,20,10,0]}
df = pd.DataFrame(my_data)
print(df)
# Team Genre Data1 Data2
# 0 A alpha 1 50
# 1 B alpha 2 40
# 2 C alpha 3 30
# 3 A beta 3 20
# 4 B beta 2 10
# 5 A beta 1 0
グループ分け結果は見やすいように可視化しているので、ぜひ参考にしてみてください。
列の要素|by="列名"
最も基本的なグループ分け方法です。
分類項目が特定の列にある場合に使用します。
.groupby(by="列名")by=は省略化能
サンプルデータをもとに適用例を見てみましょう。
df_visualized = df.groupby("Team").apply(lambda a:a[:])
print(df_visualized)
# Team Genre Data1 Data2
# Team
# A 0 A alpha 1 50
# 3 A beta 3 20
# 5 A beta 1 0
# B 1 B alpha 2 40
# 4 B beta 2 10
# C 2 C alpha 3 30
df_visualized = df.groupby("Genre").apply(lambda a:a[:])
print(df_visualized)
# Team Genre Data1 Data2
# Genre
# alpha 0 A alpha 1 50
# 1 B alpha 2 40
# 2 C alpha 3 30
# beta 3 A beta 3 20
# 4 B beta 2 10
# 5 A beta 1 0
想定通り分類されていますね。
各グループの合計を集計すると次のようになります。
df.groupby("Genre").sum()
# Data1 Data2
# Genre
# alpha 6 120
# beta 6 30
複数列の要素|by=["列名1", "列名2"…]
2つ以上の列の要素をもとに分類したい場合に使用します。
.groupby(by=["列名1", "列名2"…])- by=は省略化能
サンプルデータをもとに適用例を見てみましょう。
df_visualized = df.groupby(["Team", "Genre"]).apply(lambda a:a[:])
print(df_visualized)
# Team Genre Data1 Data2
# Team Genre
# A alpha 0 A alpha 1 50
# beta 3 A beta 3 20 #Aのbetaグループに注目
# 5 A beta 1 0 #Aのbetaグループに注目
# B alpha 1 B alpha 2 40
# beta 4 B beta 2 10
# C alpha 2 C alpha 3 30
コラム名がマルチインデックスで結果が出力されましたね。
今回の例では、(A, beta)のグループのみ要素が2つで、他のグループは要素が1つです。
sum()で合計を計算すると、(A,beta)の結果がグループ内要素の合計になることを確認してみます。
df.groupby(["Team", "Genre"]).sum()
# Data1 Data2
# Team Genre
# A alpha 1 50
# beta 4 20 #Aのbetaグループの要素の合計になっている
# B alpha 2 40
# beta 2 10
# C alpha 3 30
確かに(A,beta)の結果がグループ内要素の合計になりましたね。
インデックス列|level=0
分類項目がインデックス列にある場合に使用します。
.groupby(level=0).groupby(by="インデックス名")"インデックス名"が設定されている場合のみ有効
実行例を紹介するために、まずサンプルデータのインデックス列を変更します。
df_ind = df.set_index("Team")
print(df_ind)
# Genre Data1 Data2
# Team
# A alpha 1 50
# B alpha 2 40
# C alpha 3 30
# A beta 3 20
# B beta 2 10
# A beta 1 0
"Team"列をインデックスに変更したDataFrameを作成しました。
インデックス操作の詳しい解説は以下の記事を参照してください。

早速インデックス列でグループ分けしてみます。
df_visualized = df_ind.groupby(level=0).apply(lambda a:a[:])
print(df_visualized)
# Genre Data1 Data2
# Team Team
# A A alpha 1 50
# A beta 3 20
# A beta 1 0
# B B alpha 2 40
# B beta 2 10
# C C alpha 3 30
インデックス列に名前が割り当てられているので、by="インデックス名"でもOKです。
df_visualized = df_ind.groupby(by="Team").apply(lambda a:a[:])
print(df_visualized)
# Genre Data1 Data2
# Team Team
# A A alpha 1 50
# A beta 3 20
# A beta 1 0
# B B alpha 2 40
# B beta 2 10
# C C alpha 3 30
想定通り分類されています。
各グループの合計を集計すると次のようになります。
df_ind.groupby(level=0).sum()
# Data1 Data2
# Team
# A 5 70
# B 4 50
# C 3 30
ところで、level=0を指定する場合の引数名は、なぜlevelなのでしょうか?
これは次のマルチインデックスの場合を見てみるとすっきり理解できます。
マルチインデックス|level=[i,j,…]
分類項目がインデックス列にある場合に使用します。
.groupby(level=[i, j,…])i,jはマルチインデックスのレベル(一番外側が0に対応)
.groupby(by=["インデックス名1", "インデックス名2"])"インデックス名"が設定されている場合のみ有効
実行例を紹介するために、まずサンプルデータのインデックス列を変更します。
df_mind = df.set_index(["Team","Genre"])
print(df_mind)
# Data1 Data2
# Team Genre
# A alpha 1 50
# B alpha 2 40
# C alpha 3 30
# A beta 3 20
# B beta 2 10
# A beta 1 0
このマルチインデックスのDataFrameをもとに適用例を見てみましょう。
df_visualized = df_mind.groupby(level=[0,1]).apply(lambda a:a[:])
print(df_visualized)
# Data1 Data2
# Team Genre
# A alpha 1 50
# B alpha 2 40
# C alpha 3 30
# A beta 3 20 #Aのbetaグループに注目
# beta 1 0 #Aのbetaグループに注目
# B beta 2 10
マルチインデックスで分類された結果が出力されましたね。
インデックス列に"インデックス名"が設定されている場合は、by=["インデックス名1", …]でもOKです。
df_visualized = df_mind.groupby(by=["Team","Genre"]).apply(lambda a:a[:])
print(df_visualized)
# Data1 Data2
# Team Genre
# A alpha 1 50
# B alpha 2 40
# C alpha 3 30
# A beta 3 20 #Aのbetaグループに注目
# beta 1 0 #Aのbetaグループに注目
# B beta 2 10
【上級編】関数適用でグループ分け|by=func
インデックス列の要素に関数を適用して、何らかの分類処理を行ってから分類することも可能です。
例えば、次のような条件で分類するケースです。
- 文字列の頭文字を抽出して分類
- 数値が特定の条件(奇数か偶数かなど)を満たすかを条件に分類
- 日付データの年代で分類
次のサンプルDataFrameで挙動を確認してみましょう。
df_ind = df.set_index("Team")
print(df_ind)
# Genre Data1 Data2
# Team
# A alpha 1 50
# B alpha 2 40
# C alpha 3 30
# A beta 3 20
# B beta 2 10
# A beta 1 0
分類処理を行う関数の例として、母音であれば"vowel"、子音であれば"consonant"を返すだけの関数を作成してみます。
def grouping_by_letter_type(letter):
if letter in "AEIOU":
return "vowel"
else:
return "consonant"
この関数をもとにサンプルDataFrameをグループ分けしてみます。
df_visualized = df_ind.groupby(by=grouping_by_letter_type).apply(lambda a:a[:])
print(df_visualized)
# Genre Data1 Data2
# Team
# consonant B alpha 2 40
# C alpha 3 30
# B beta 2 10
# vowel A alpha 1 50
# A beta 3 20
# A beta 1 0
関数を適用してバッチリグループ分けできましたね。
これで列やインデックス列を指定してグループ分けする方法はだいたい大丈夫だと思います。
グループごとの関数適用方法
各グループへの関数適用方法を紹介します。
次の順番で、少しずつ応用編へと進んでいきましょう。
- よく使う基本関数まとめ
.agg()による様々な集計- 任意の関数適用|
.agg(my_func) - 同時に複数関数を適用|
.agg(["集計名"…]) - 列毎に異なる関数適用|
.agg({"列名": 集計名}) - 集計後のラベル名指定|
.agg(**{ラベル名指定})
よく使う基本関数まとめ
.groupby()に適用できる主な関数は下表の通りです。
| 関数名 | メソッド名 |
|---|---|
| 平均 | .mean() |
| 最大 | .max() |
| 最小 | .min() |
| 中央値 | .median() |
| 標準偏差 | .std() |
| データ数 | .count() |
これらの関数を覚えておけば、一通りは対応できるかと思います。
次のサンプルDataFrameを使用して、基本関数の適用挙動を確認してみましょう。
my_index = ["A", "B", "C", "A", "B", "A"]
my_data = {"Data1":[1,2,3,3,2,1], "Data2":[50,40,30,20,10,0]}
df = pd.DataFrame(my_data, index=pd.Index(my_index, name="Team"))
print(df)
# Data1 Data2
# Team
# A 1 50
# B 2 40
# C 3 30
# A 3 20
# B 2 10
# A 1 0
.mean()、.max()、.min()、.std()を適用した例を紹介します。
df.groupby("Team").mean()
# Data1 Data2
# Team
# A 1.666667 23.333333
# B 2.000000 25.000000
# C 3.000000 30.000000
df.groupby("Team").max()
# Data1 Data2
# Team
# A 3 50
# B 2 40
# C 3 30
df.groupby("Team").count()
# Data1 Data2
# Team
# A 3 3
# B 2 2
# C 1 1
組み込みの関数であれば簡単に適用できますね。
その他の組み込み関数については、公式ドキュメントを参照してください。
.agg()による関数適用・様々な集計
.aggregate() or .agg()を使用すると、様々な形式で関数を適用、集計することができます。
.agg()は、.aggregate()のエイリアス(別名)なので、挙動は同じです。
ここでは、以下の4つの応用手法を紹介します。
- 任意の関数適用|
.agg(my_func) - 同時に複数関数を適用|
.agg(["集計名"…]) - 列毎に異なる関数適用|
.agg({"列名": 集計名}) - 集計後のラベル名指定|
.agg(**{ラベル名指定})
一つずつサンプルコードを使用しながら紹介していきます。
任意の関数適用|.agg(my_func)
.agg()を使用すると、条件を満たした任意の関数を適用できます。
df.groupby("列名").agg(function)functionはarray_likeを引数にする関数|function( array_like )
例として、NumPyのnp.sum()関数を適用してみます。
import numpy as np
df.groupby("Team").agg(np.sum)
# Data1 Data2
# Team
# A 5 70
# B 4 50
# C 3 30
次に自作の関数, my_funcを適用する例を紹介します。
自作関数, my_funcは、引数がarray_likeとなるように作成します。
def my_func(array_like):
return (max(array_like) - min(array_like))
x = [2, 10, 3]
print(my_func(x))
# 8
この関数は、引数のarray_likeの最大値と最小値の差を計算する関数ですね。
この自作関数を.groupby().agg()で適用してみましょう。
df.groupby("Team").agg(my_func)
# Data1 Data2
# Team
# A 2 50
# B 0 30
# C 0 0
.agg()を使えば、自作関数での集計も簡単に実行できますね。
同時に複数関数を適用|.agg(["集計名"…])
.agg()メソッドを使用すると、同時に複数の関数を適用できます。
引数として、集計名("max"など)または関数名(np.sumなど)のリストを渡します。
df.groupby().agg([ "集計名1", "集計名2", 関数名3, 関数名4…])
df.groupby("Team").agg(['min', 'max', np.sum])
# Data1 Data2
# min max sum min max sum
# Team
# A 1 3 5 0 50 70
# B 2 2 4 10 40 50
# C 3 3 3 30 30 30
関数が複数なので、マルチインデックスになっていますね。
列毎に異なる関数適用|.agg({"列名": 集計名})
ある列は合計、ある列は平均を計算したい場合もあるかと思います。
.agg()メソッドを使用すると、列ごとに異なる集計をすることも可能です。
その場合、引数として{列名: 適用関数}を要素とする辞書を渡します。
df.groupby().agg({"列1": 集計方法1, "列2": 集計方法2, …})適用関数:関数名("max"など)、関数(np.sumなど)またはそれらのリスト
各列に異なる集計を適用した例をみて見ましょう。
df.groupby("Team").agg({"Data1":"sum", "Data2":np.sum})
# Data1 Data2
# Team
# A 5 70
# B 4 50
# C 3 30
各列に、価格だったり、個数だったり、単価だったり、いろいろなデータが混ざっているときの集計時に力を発揮しそうな機能ですね。
とは言っても、列名が"Data1"や"Data2"では何を計算したかがわかりにくいです。
次にラベル名も変更する方法を紹介します。
集計後のラベル名指定|.agg(**{ラベル名指定辞書})
.agg()の引数を指定することで、集計後のラベル名を変更する方法を2つ紹介します。
.agg()の引数を次の形式で渡します。
.agg( 変更後ラベル名1 = ("列名1", 適用関数), …).agg( **{"変更後ラベル名1": pd.NamedAgg(column="列名1", aggfunc=適用関数), …} )
1つ目は直感的ですが、変更後ラベル名が"文字列"ではなく「ベタ打ち」なので自由度が低いです。
2つ目は変更後ラベル名も変数で指定できるので、自由度が高いですね。
# .agg( 変更後ラベル名1 = ("列名1", 適用関数), …)
df.groupby("Team").agg(Data1_sum=("Data1", "sum"), Data2_mean=("Data2", "mean"))
# .agg( **{"変更後ラベル名1": pd.NamedAgg(column="列名1", aggfunc=適用関数), …} )
df.groupby("Team").agg(**{"Data1_sum": pd.NamedAgg(column="Data1", aggfunc=sum),
"Data2_mean": pd.NamedAgg(column="Data2", aggfunc="mean") })
# Data1_sum Data2_mean
# Team
# A 5 23.333333
# B 4 25.000000
# C 3 30.000000
2つ目の方が設定の自由度は高いのですが、冗長になってしまうのが欠点ですね。
グループごとにデータ加工|.transform()
.transform()を使用すると、グループ内のデータ使用して、データを加工した新たなDataFrameを作成することができます。
このとき、出力結果は元のDataFrameと同じサイズのDataFrameになります。
少し難しい部分があるので、次の図で.transform()のイメージを整理してみましょう。
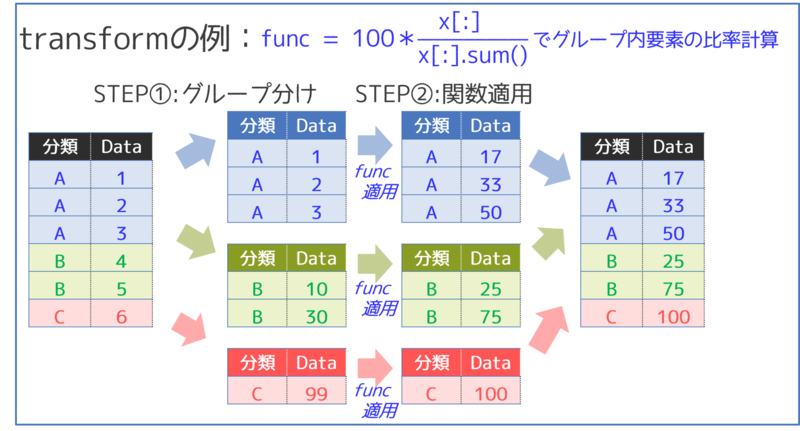
②で特定の関数をグループごとに適用して、グループ内のデータを加工しています。
最後にグループを結合しなおして、新たなDataFrameを生成していますね。
.transform()のポイントは、引数の関数functionの作り方にあります。
df.groupby("列名").transform(function)
このときfunctionは、次のような関数です。
array_likeを引数にする関数|function(array_like)→array_like'- 引数の
array_likeと結果のarray_like'は同じサイズ
次のサンプルDataFrame用いて、.transform()の挙動を確認してみましょう。
my_index = ["A", "A", "A", "B", "B", "C"]
my_data = {"Data1":[1,2,3,10,30,99]}
df = pd.DataFrame(my_data, index=pd.Index(my_index, name="Team"))
# Data1
# Team
# A 1
# A 2
# A 3
# B 10
# B 30
# C 99
次のようにarray_likeを渡して、各要素の比率を計算する関数を考えてみます。
def calc_proportion(array_like):
return np.round(array_like / array_like.sum()*100)
x = np.array([1, 2, 2])
print(calc_proportion(x))
# [20. 40. 40.] <-引数xと同じサイズのarray_likeが返されている
この関数で次のDataFrameを.transform()してみます。
df.groupby("Team").transform(calc_proportion)
# Data1
# Team
# A 17.0
# A 33.0
# A 50.0
# B 25.0
# B 75.0
# C 100.0
グループ内のデータ使用して、データを加工した新たなDataFrameを作成していますね。
.transform()の返すDataFrameは、もともとのDataFrameと同じ行数なので、次のようにもとのDataFrameに列を追加することが可能です。
df["Prop"] = df.groupby("Team").transform(lambda x:round(x/x.sum()*100))
# Data1 Prop
# Team
# A 1 17.0
# A 2 33.0
# A 3 50.0
# B 10 25.0
# B 30 75.0
# C 99 100.0
おわりに|padans関連おススメ追加コンテンツ
今回はpandasの.groupby()について解説しました。
pandasは便利すぎて操作方法がわかりにくいことがよくあります…。
結局はコツコツ学ぶのが、pandasマスターの近道ですよね!≫【ブログカテゴリー:pandas】











